Did you know about binary golfing? I did not and stumbled upon the Binary Golf Grand Prix 4 call for submission recently by accident. The goal of the 2023 competition is to write the smallest file that would:
- produce exactly one copy of itself, named "4"
- print, return, or display the number 4
So basically, a program that self-replicates (once at least). You know, like Hacker's rabbit virus ^^. It is a fun initiative and I wanted to give it a try, competing in the .PYC category. While I am neither a binary golfing nor a python expert, I had to write a .PYC file parser and disassembler for Malcat that gave me some base knowledge. So let's see if Malcat is up to the task! Worst case scenario it will make a good tutorial for Malcat's editing capabilities.
Edit: the results are out and our .pyc file won first place (out of 4)
Initial program (218 bytes)
For those new to python, when you run a python script myfile.py for the first time, python creates a myfile.pyc on the disk in order to cache the compiled bytecode of the script. This will speed up the next execution of your script.
Did you know: you can also force python to produce a .PYC file by running the command
python -m compileall myfile.py
So let's give it a try with a very simplistic and minimal python script named stage1.py:
1 2 3 4 | |
We'll compile our example and test if everything runs smoothly:
1 2 3 4 5 6 7 8 9 | |
On my computer, the .pyc file has a size of 218 bytes, but this size may vary depending on your version of python and where you have compiled your script (we'll come to this later). This is relatively big for such a small program, let's see what we can do.
Source-level optimisation (203 bytes)
Before diving into the intrinsics of the .PYC file format, there are a few simple optimisations that we can apply to this small program to save a few bytes. If we read carefully the call for submission of the Binary Golf Grand Prix 4, we can see very few little constraints are given. And what is in particular interesting is that we can chose freely:
- the name of the submitted file
- the python version we use
Changing the name
First let's play around with the name of the file. Like Java or .NET, the python bytecode is a constant-pool based format where all constants, class names, variables names, etc. are stored in a file area known as the constant pool, and the bytecode of the program merely refers to this constant pool. That's also the case of the __file__ variable that we use in our script, which ends up in the constant pool and uses more than 8 bytes on disk!
So let us abuse a feature of the python interpreter which can recognize and execute .PYC file regardless of their extension: what if we renamed our file let's say "a":
1 2 3 4 | |
Let us compile, rename and run the program:
1 2 3 4 5 6 7 | |
We saved 7 bytes, great! That was easy. What can we do now without touching the .pyc file format? Well, we could try another python version.
Impact of python version
Like any program, the python compiler has been slowly adding features since its 1.0 version. More features means a more complex .pyc format. And who says more complex often says bigger. By using a lower python version, we can most likely save a few bytes. Since I still want my sample my program to be run, we'll ignore old unsupported python versions. I think using python 3.6 is a good compromise, since it's still capable to run on ubuntu 18.04 which had it end of support for a couple of months. So let's see what happens if we compile our program using python 3.6:
$ python3.6 -m compileall stage2.py
$ mv __pycache__/stage2.cpython-36.pyc a
$ python a
> 4
$ ls -l
> -rw-r--r-- 1 malcat Aucun 203 Jul 4 17:19 a
> -rw-r--r-- 1 malcat Aucun 203 Jul 4 17:19 4
Wow, another 8 bytes saved! If like me you are curious where the difference come from, you can diff your two .pyc files using Malcat:
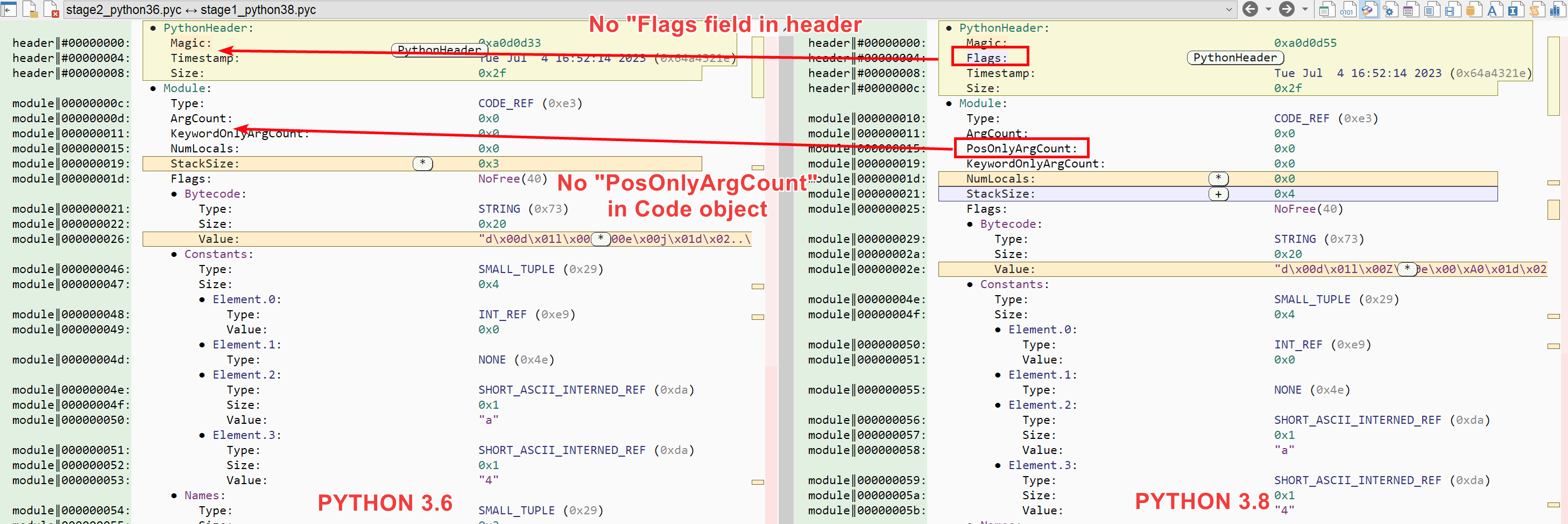
We can see here that two new fields have been added in python 3.8:
- a
Flagsfield in the python header - a
PosOnlyArgCountfield in the code object structure
Those two fields being of type uint32, it means that the python 3.6 version of our program needs 8 bytes less to be serialized on disk, it makes sense.
Removing debug informations (132 bytes)
Now is time to dig into our generated .pyc file and see if we can save some bytes. The .pyc file format is very simple and composed of a small python header, followed by the marshalled code object of your module. The python header has very few useful information:
- A magic value, which tells python this is a
.pycfile and also which python version it targets (the magic value changes with each python release) - A timestamp (time of compilation)
- A size field, which seems to be the size of the originating
.pyfile
The code object that follows is much more interesting and is composed of four main areas:
- The bytecode of the module, that is the code run at a global scope (aka the module constructor)
- The constant pool, which holds all constants (dicts, strings, numbers, etc.)
- The names list, which contains all module and variable names used by the bytecode
- Some debug information, used to reconstruct a nice stacktrace in case of exception
This format is pretty strict. As far as I know, any attempt to modify the ground structure of this marshalled object leads to an error. Since removing parts of the .pycfile seems out of question, let us see if we can at least optimize its content.
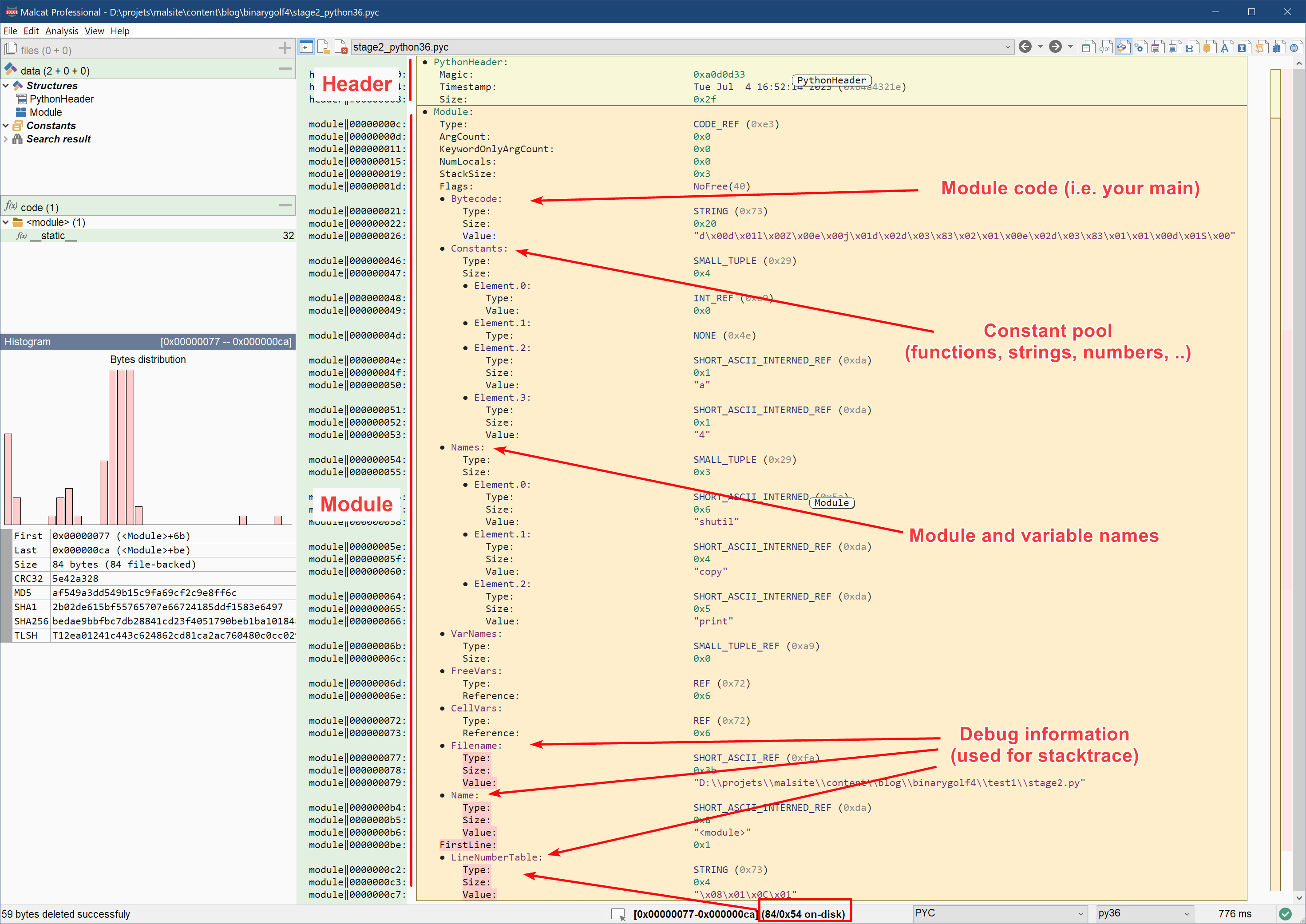
The first thing that we notice is that debug informations, at the end of the .pyc file, take a lot of space: 84 bytes! About 2,5 times the space that the actual bytecode uses. The debug informations are composed of three fields, used mainly to display nice stack traces when the program crashes:
- The
Filenamefield which contains the path to the original.pyscript - The
Namefield which contains the name of our module - The
LineNumberTablefield which contains a mapping from bytecode offsets to line numbers
Since our very simple program is unlikely to crash, we can try to get rid of these three fields. Simply removing them won't do, since they are required for the .pyc file to run. But nothing speaks against setting their content to the empty string. How to do this? Just set the three Size fields to 0. Then, select the Value fields, and delete the selection (Right click > Selection > Remove selected bytes). If needed, you can always reanalyse the file using the keyboard shortcut Ctrl+R. Here is an example below:
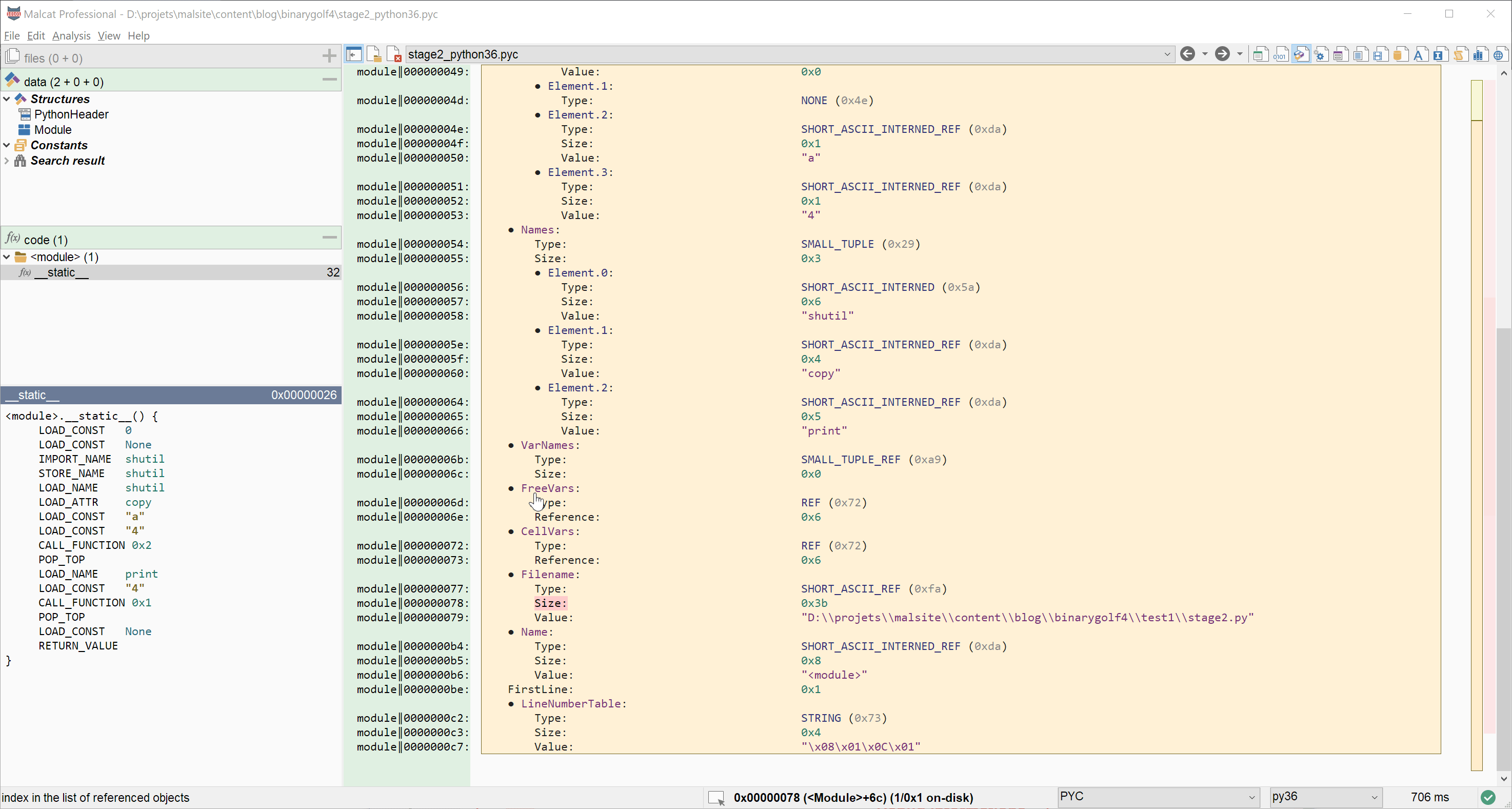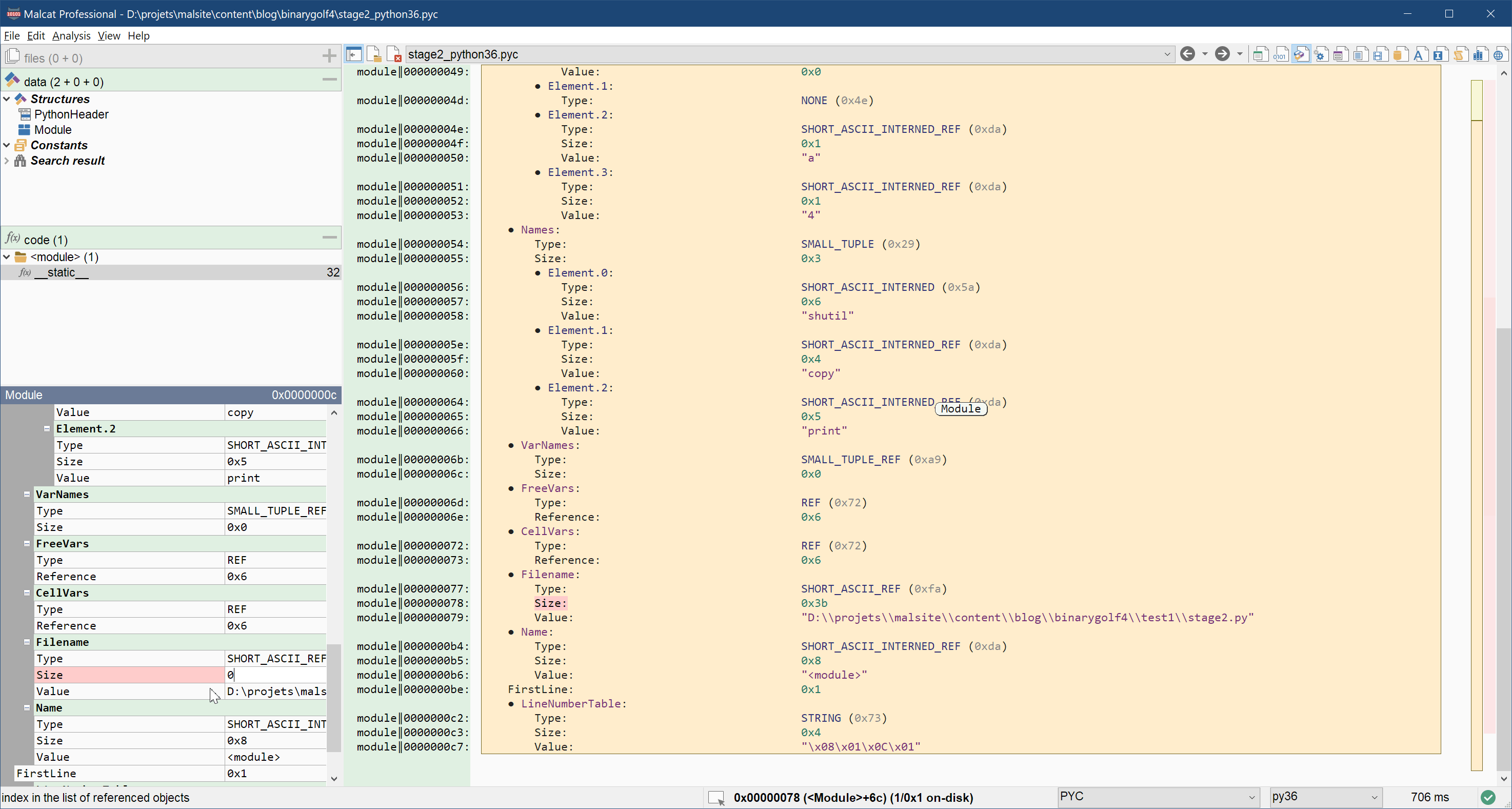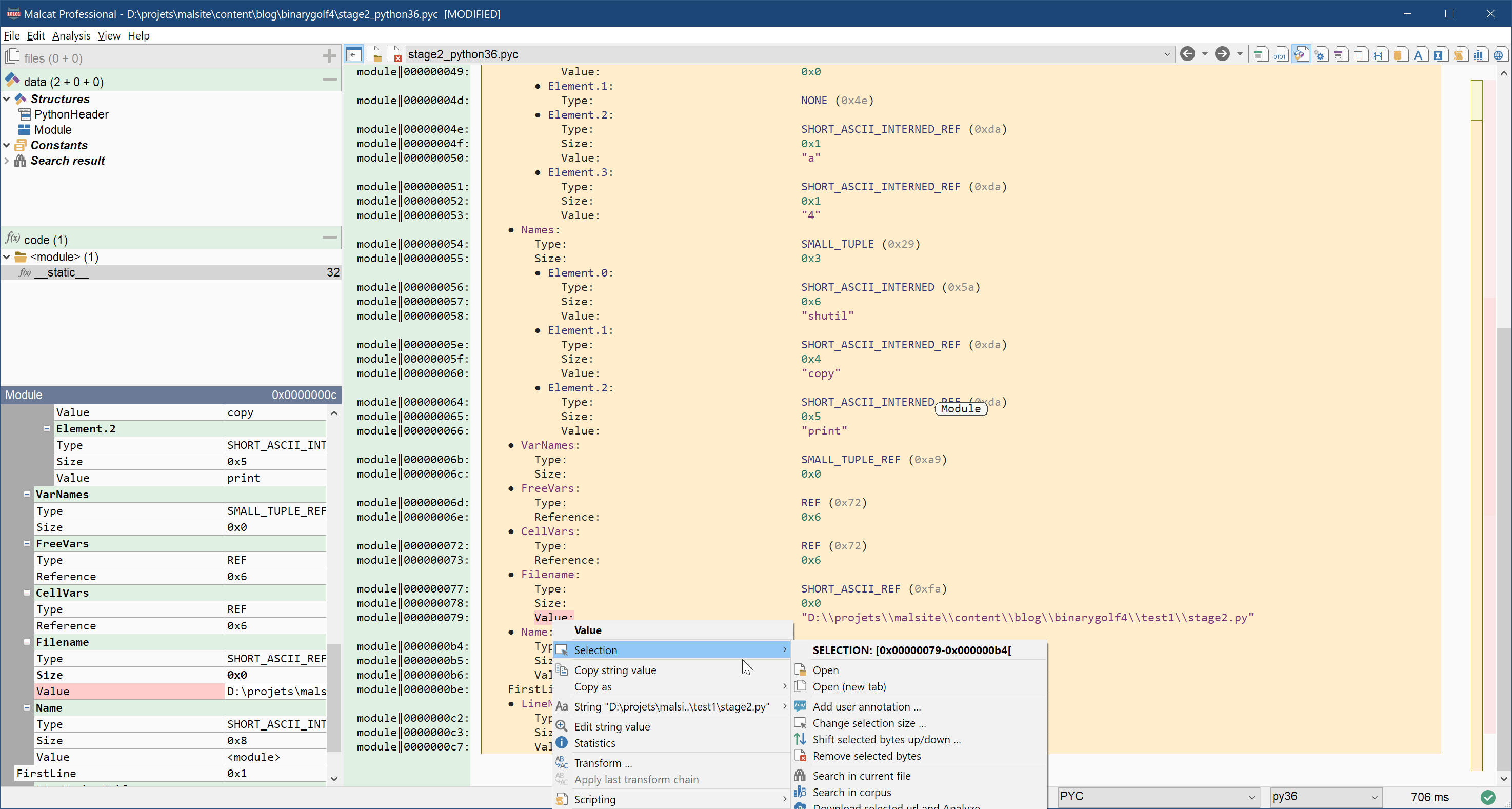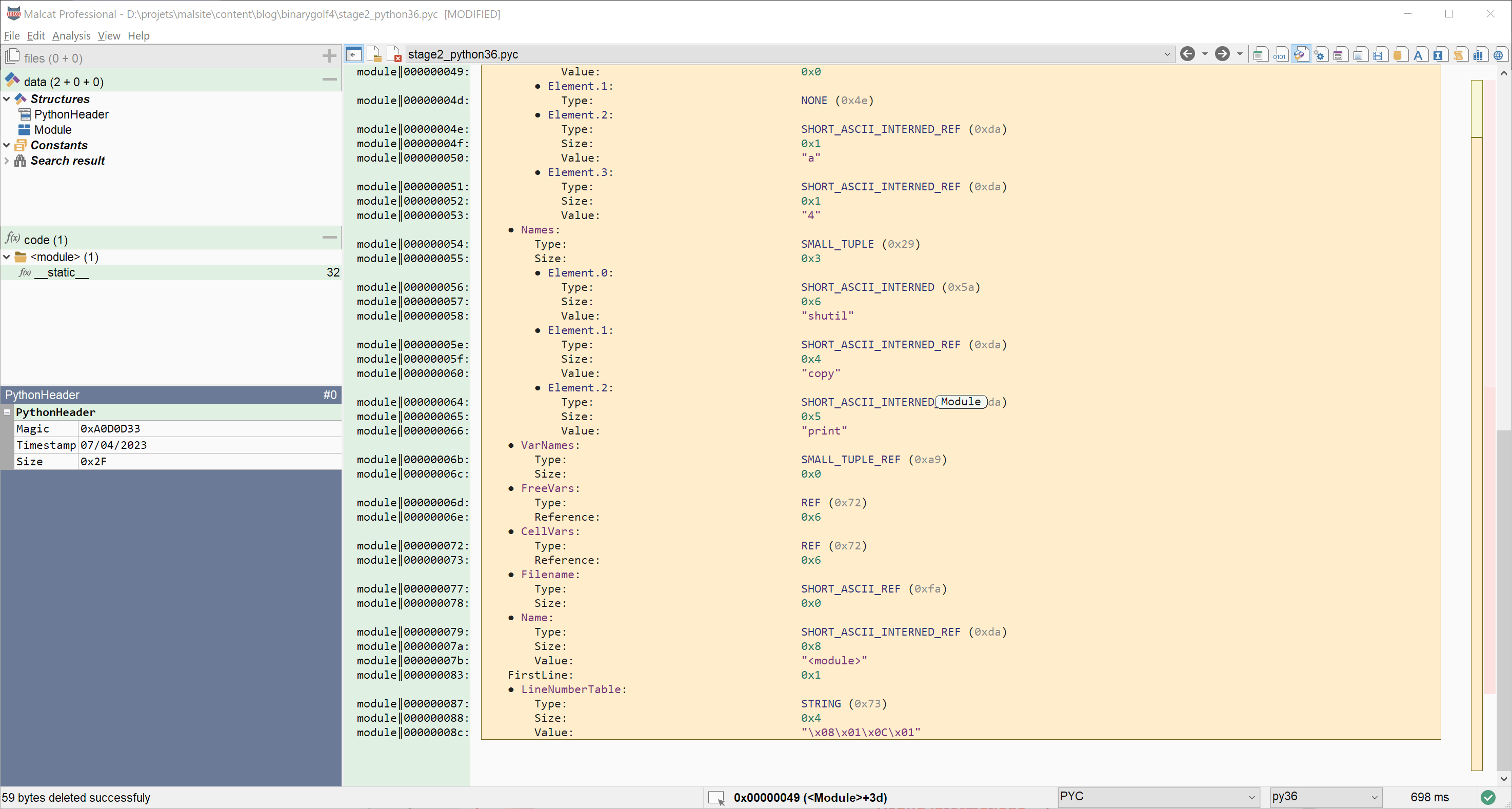
Does it work still? Sure, and the .pyc file is now only 132 bytes big!
1 2 3 4 5 | |
Optimising the bytecode (120 bytes)
The current bytecode
With the debug informations out of the way, it is now time to have a look at the main dish: the actual bytecode. Our python script was really tiny: only 3 lines. If you own a full or pro version of Malcat (which supports python disassembly), you can have a look at the emitted bytecode. If not, just have a look at the annotated disassembly listing below.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |
In python 3, most bytecodes are encoded on 2 bytes. So 16 opcodes * 2 bytes gives us 32 bytes total. That seems a lot for 3 lines of python. Let us see if we can reduce this a bit.
Optimisation
The Python virtual machine is stack-based: no registers, no memory operands, just the stack and meta tables indices. So our effort will focus mostly on stack optimisation. We can already make the following observations:
- Line 4-5 The
shutilmodule object, after being fetched via the IMPORT_NAME opcode, gets saved and then reloaded to thenamesdictionary, which seems unnecessary since we only use it once. - Line 2 & 13-14 We push
Noneon the stack in Line 2, andNoneis returned by the call toprint()and discarded from the stack on Line 14. This seems wasteful. - Line 10 & 15-16 Python code at the module level doesn't return anything. So Line 16 we can return anything: it will be ignored by python. We could use another discarded stack value, like whatever
shutil.copy()returns at Line 10 and save another opcode.
So let us write down our battle plan:
- Start with the
print()call in order to reuse itsNonereturn value as parameter for the IMPORT_NAME opcode - Get rid of the useless
STORE_NAME/LOAD_NAMEcombo. - Use the return value of the
shutil.copy()call as return value for the module global function
This should additionally allow us to remove several useless POP_TOP opcodes and save even more space. At the end, the reordered and optimized bytecode will look like:
1 2 3 4 5 6 7 8 9 10 | |
That's only 10 opcodes, making a grand total of 20 bytes. We saved 12 bytes, not bad!
Patching the optimized bytecode
Now when patching the byte code, we have to bit a bit careful. See, the complete constant pool is following the bytecode object, so if we remove bytes, this will shift every data and mess everything up if we don't update the Size field of the bytecode object in parallel.
So we will do it in three steps in Malcat:
- Reorder the bytecode as we want and put all opcode we don't need at the end the function
- Update the Size field of the bytecode object
- Delete the opcodes we don't want at the end of the method
Below you can see the code patching process in action using Malcat:
I've found that it is the fastest way to patch the bytecode, but feel free to try your own way.
Tip: by default, Malcat will reanalyse the whole file after every byte insert/removal. Sometimes it can get in our way, but you can disable this behavior in Preferences > General > Reanalyse file after insert/delete.
Trimming the constant pool (113 bytes)
When optimization ruins optimization
When a python program is first loaded, all objects in its constant pool are instantiated. But creating a new python object comes with a cost: it needs to be allocated and initialized. And that's an issue for large constant pools.
In order to reduce startup time and memory usage, all constants in the constant pool are defined (and instantiated) only once. All identical copies of an object in the constant pool / names array are replaced by a special token called a reference. This reference points to the first definition of the object. And why do we care will you ask? Well, a reference token is composed of:
- Its type: the number
114stored in one byte - the referenced object index: a number stored on 4 bytes
And sometimes, the reference to the object takes more place on disk than the object itself! That is indeed the case in our .pyc file for the fields FreeVars and CellVars, which are references to the empty tuple in the Varnames field. The original empty tuple defined in Varnames takes 2 bytes on disk, while the two references to this empty tuple in FreeVars and CellVars field take each 5 bytes!
So let us replace these 2 references by the serialized empty tuple object, which is composed of two bytes { 29 00 }. For an easy edit, you can also use Malcat's field editor:
This lets us save 6 bytes, great!
None is gone
We have optimized the bytecode of the main function and as a side effect we have removed all references to the None constant in the bytecode. But the constant declaration for None still remains in the constant pool and takes one byte! Of course we have to remove it. But we have to be careful: if we remove one entry in the constant pool, the entries below are shifted up and have their index logically decremented by one. But since the LOAD_CONST bytecode references constants by their constant pool index, we will have to patch the LOAD_CONST instructions accordingly. Fortunately, there are only three locations to patch, as we can see below:
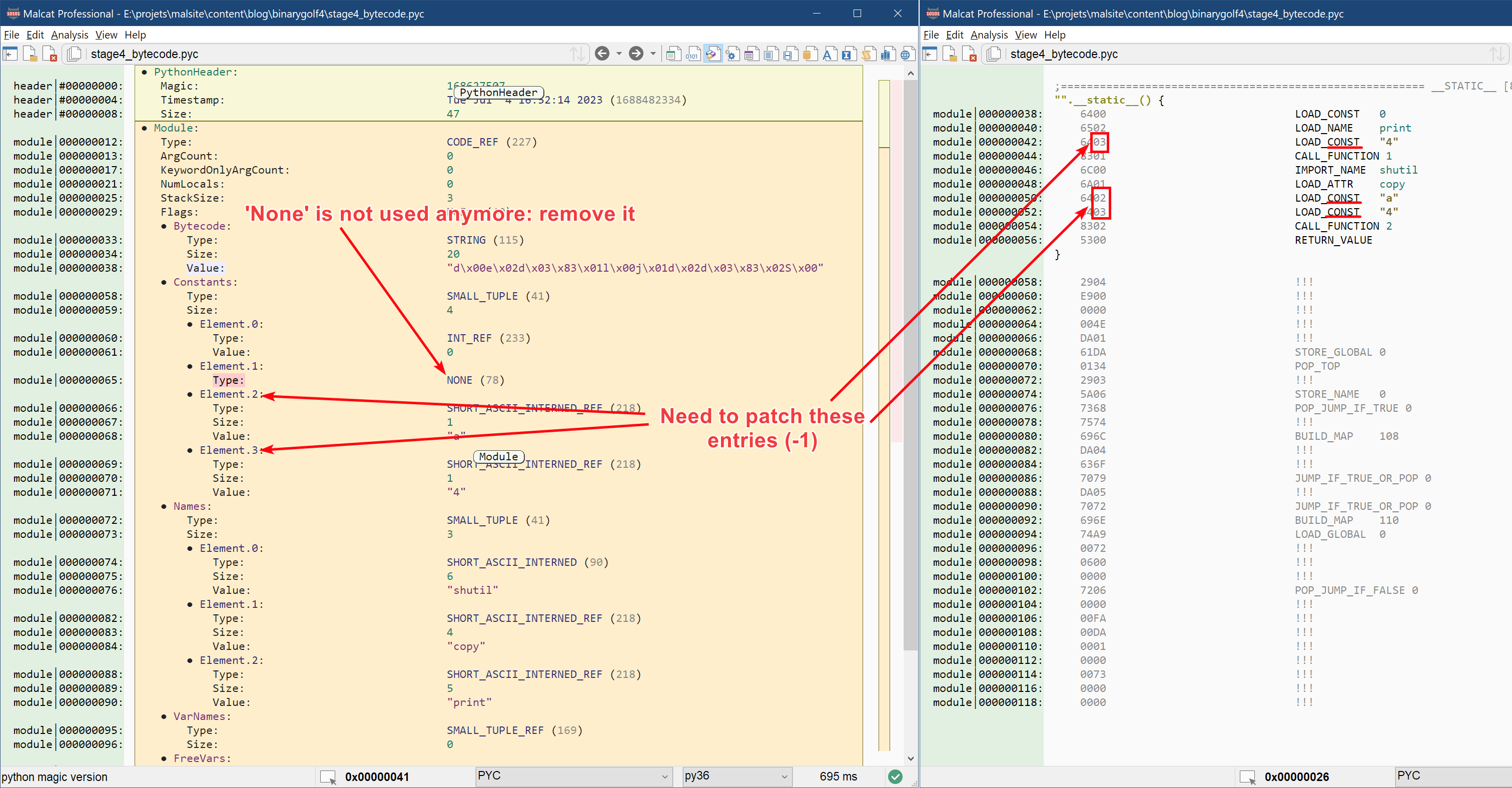
The easiest way is to edit the bytecode manually from within the disassembly view (F3). Just double-click on the byte you want to edit (in the hexadecimal column) and decrement it.
And after this last edit, we have trimmed our .pyc file to ... 113 bytes! A good place to end our efforts, since I was running short on optimization ideas anyway.
Conclusion
This Binary Golf Grand Prix 4 challenge was rather fun at the end and I did like the very simple rules: it is easy to make a submission, but making a winning one requires good knowledge of the file format.
While python serialized bytecode format (.pyc) is relatively strict and does not offer much liberty for clever tricks, we were still able to divide the size of our original BGGP 4 entry by almost 2. We carefully optimized the bytecode, the constant pool and got rid of debug informations. Both Malcat structure editor and disassembler came in handy and at the end, the whole editing process was relatively easy.