Today we are happy to announce the release of Malcat version 0.9.10. This release brings several new and/or improved features that we are pretty excited about:
- An improved CFG recovery algorithm that can handle complex dynamic jumps / dynamic pointer calculations
- A new CPU architecture: MIPS (32 and 64 bits, LSB and MSB)
- UI improvements in the disassembler and decompiler views
- Extended corpus search
- Updated offline Kesakode database
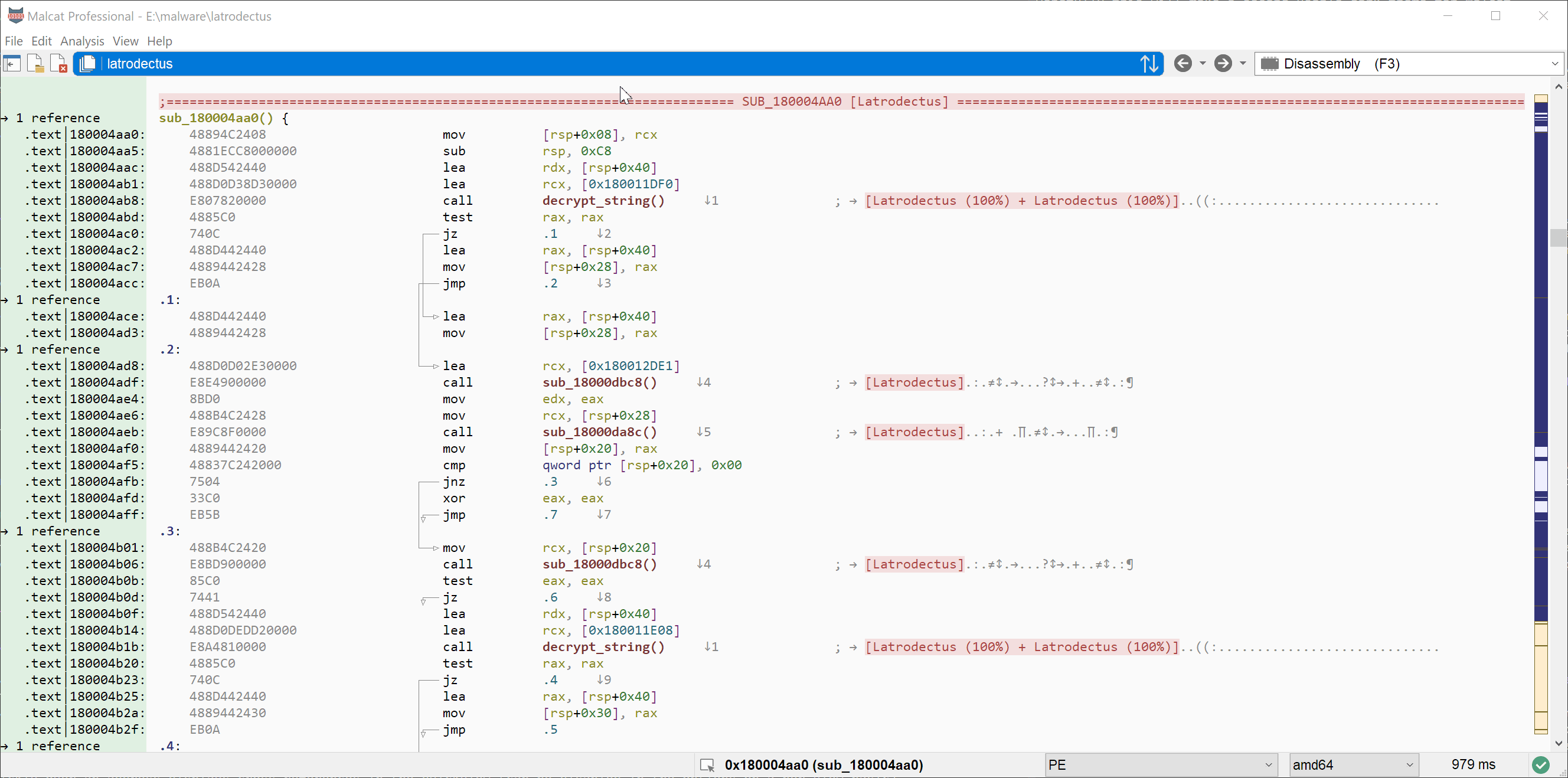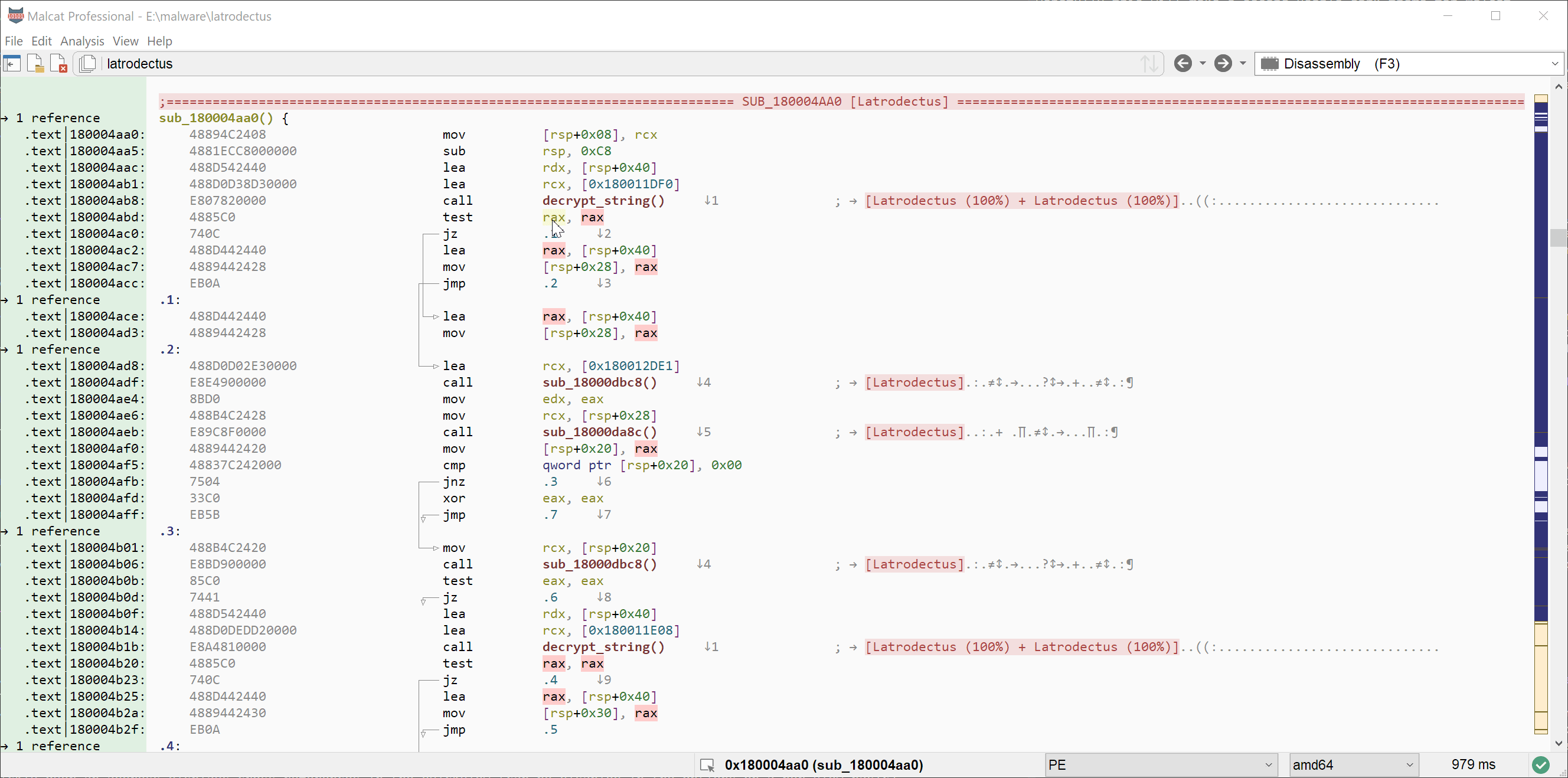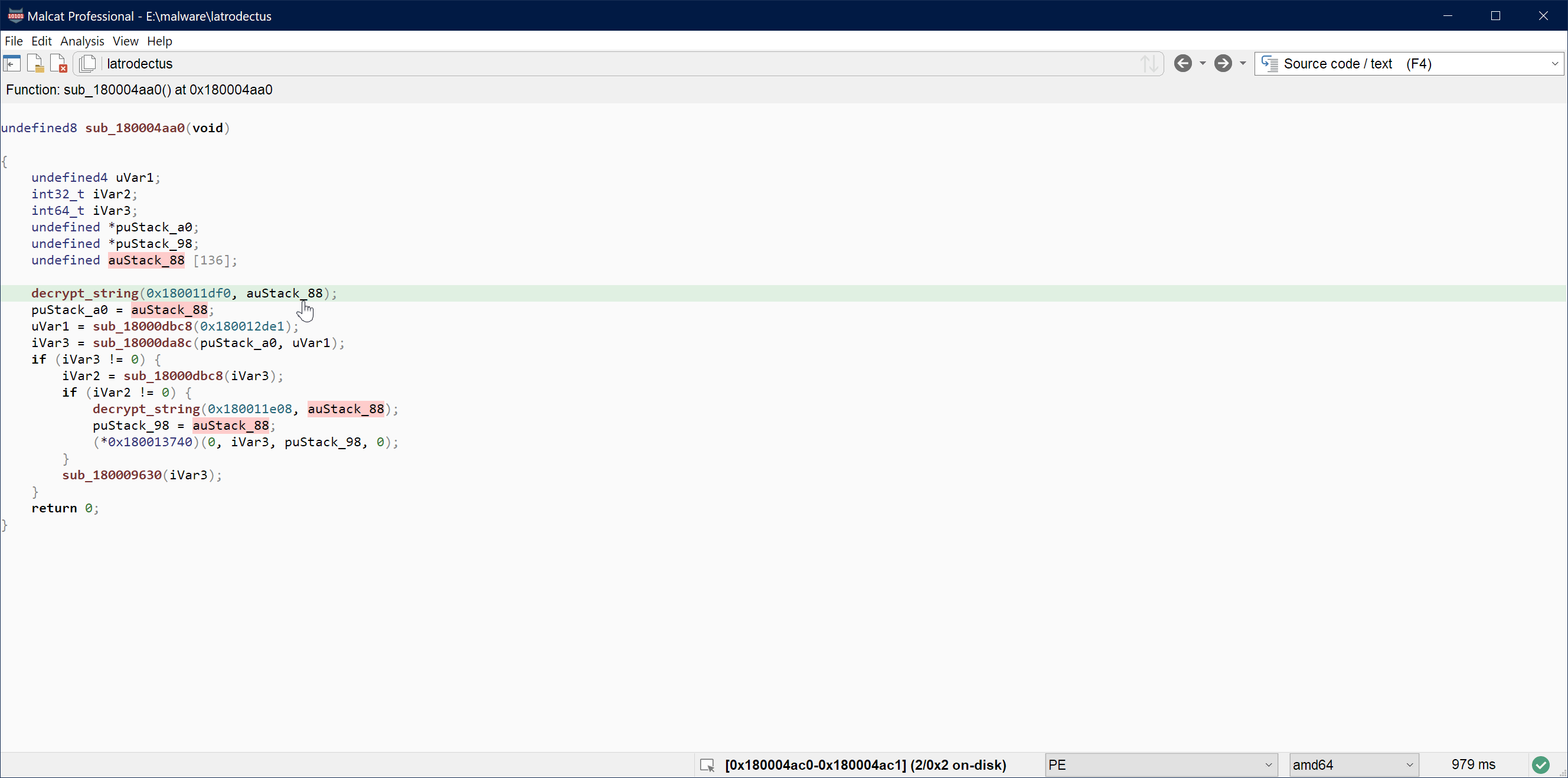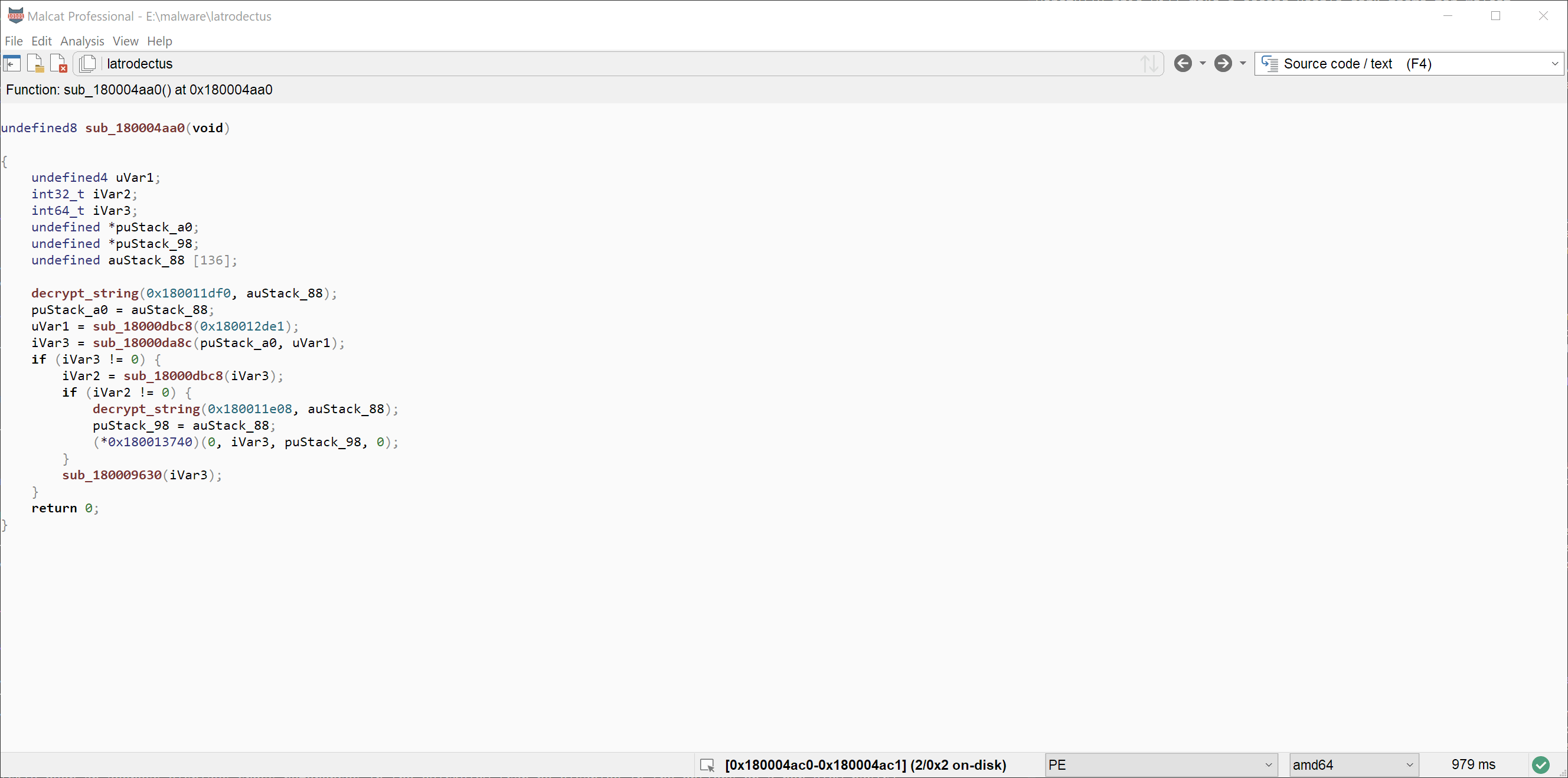
- Latrodectus config extractor
- and the usual: new transforms, anomalies, signatures, etc.
The biggest change in this release is the (much-needed) refactoring of Malcat's CFG recovery algorithm. The improved dynamic jump analysis will allow us to support RISC-like architectures that heavily rely on pointer arithmetic. The newly added MIPS disassembler is just a start!
Code analysis in Malcat
A large amount of Malcat's power stems from its code analysis abilities. This is key not only for you fellow reverse engineers, but also for many of Malcat features such as Kesakode, our Malware identification technology.
Since the first launch of Malcat's beta (4 years ago now, wow), we have added several CPU architectures to Malcat, but the core of the analysis stayed the same, with some of its early weaknesses. In particular, dynamic jump resolution (e.g. switch resolution or vtable calls) was never Malcat's strong-suit. Some heuristics were in place (mostly constant propagation at a basic-block level) but they were not able to deal with complex pointer computations.
In this release, we have thus invested a significant amount of dev time to improve this part of the analysis. We have completely redesigned how CFG recovery works in Malcat and added a new abstract-interpretation based analysis tailored toward pointer arithmetic. This is the type of analysis you can typically find in pure reverse engineering software such as IDA, Binary Ninja or Ghidra. So let us have a look!
What is CFG recovery?
Control-Flow Graph (CFG) recovery is a crucial process in reverse engineering and decompilation, where the goal is to reconstruct the control-flow graph of a binary program. This graph represents the flow of execution within the program, detailing how different parts of the code interact.
The first pitfall any CFG recovery algorithm has to overcome is how to separate the code from the data. It may sound like a simple task, but sadly we live in a von Neumann architecture world, were data and code live together in your computer's memory. Sure, the ELF or PE file formats give you some information, such has "this is a code section" or "this contains read-only data", but these are merely hints. You can find data in code sections (e.g. switch tables, or just everything if you're a Delphi program) or code in data section (if you're analysing a packer/crypter for instance).
If you somehow managed to identify all the code in the program, the second challenge would be to reconstruct the control flow graph. This means following each jump and call, both static ones where the destination is encoded in the instruction (easy) and dynamic ones where the destination is computed at run time (e.g. switch tables, hard). This comes also with additional challenges, like getting the exception flow right, identifying non-returning functions, etc.
Finally, the last challenge one has to face is to identify the function boundaries. This is a relatively easy task if the program comes with (debug) symbols, but it is very rarely the case in the world of malware analysis. Different algorithms can be used, that will each have to overcome common pitfalls such as terminal function identification or tail call analysis. Even then, function boundaries recovery has not always a single valid solution.
If you're interested in this topic, I invite you to read about all these challenges (and more) in this nice introductory paper: All You Ever Wanted to Know About x86/x64 Binary Disassembly But Were Afraid to Ask. You will see a more comprehensive list of the techniques used in contemporary reverse engineering software, both commercial and open-source.
Malcat's algorithm
Malcat's CFG recovery algorithm is divided in three phases: a code identification phase, a CFG reconstruction phase and finally the functions recovery. Each phase is described below.
First phase: separating code from data
When Malcat starts the analysis of a program, it takes a pessimistic approach: by default everything is data. Malcat will have to be convinced to consider portions of this data as code. So the first action in Malcat's code analysis pipeline (after the whole program range has been tagged as data) is to gather every potential code entries, such as:
- File format-defined entrypoints (entrypoint, .init, TLS, etc.)
- Exported functions
- Functions with debug informations
- RTTI vtables
- Known function prologs (using pattern matching, aka regexps)
- Exception handlers
- Data references (i.e. following pointers found in any non-code section)
- Small gaps between two already-identified functions (heuristic added in 0.9.10)
Each of these entry points candidates needs to be confirmed first. Malcat uses three different algorithms to verify that code is indeed real code.
The first heuristic is a simple validity test: the code flow is disassembled starting at the entry point candidate and following every jump and call. If invalid instructions are encountered, or if the control flow is directed to invalid addresses, the code entry address is rejected. The amount of disassembled instructions depends on the type of the entry point. Each potential code source comes with a risk factor associated, e.g. exported function addresses are relatively low-risk (i.e. there is a high chance that a function effectively starts there), while pointers found in a data section are high-risk. The higher the risk factor, the more instructions Malcat will disassemble before accepting the entry point candidate.
The second heuristic is an opcode frequency analysis. Malcat will compute the distribution of opcodes along the control flow following the entrypoint candidate. If the deviation of opcode frequencies to a previously-computed ground truth is too high, the address will be considered as data. The idea there is to reject code largely composed of very rarely used instructions.
The third and last heuristic will inspect the relationship between sequential instructions. Malcat will compute the probability of instruction sequences to happen against a previously computed ground truth stored as a markov chain. If too many odd transitions are spotted (e.g. a cmp instruction followed by a call), the entry point candidate is rejected. Again, the number of transitions analysed depends on the associated risk factor.
Finally, validated code entry candidates are then passed to the second phase of Malcat's CFG reconstruction algorithm: the actual build of the code flow graph, described below.
Second phase: building the graph
Building the control flow graph once we are sure that code is indeed code is relatively straightforward. Every instruction has to be followed and added to the graph. Jumps and calls are followed too. Code references (e.g. lea ecx, <address_of_SEH_handler) are also gathered and saved for a later new pass of the first phase.
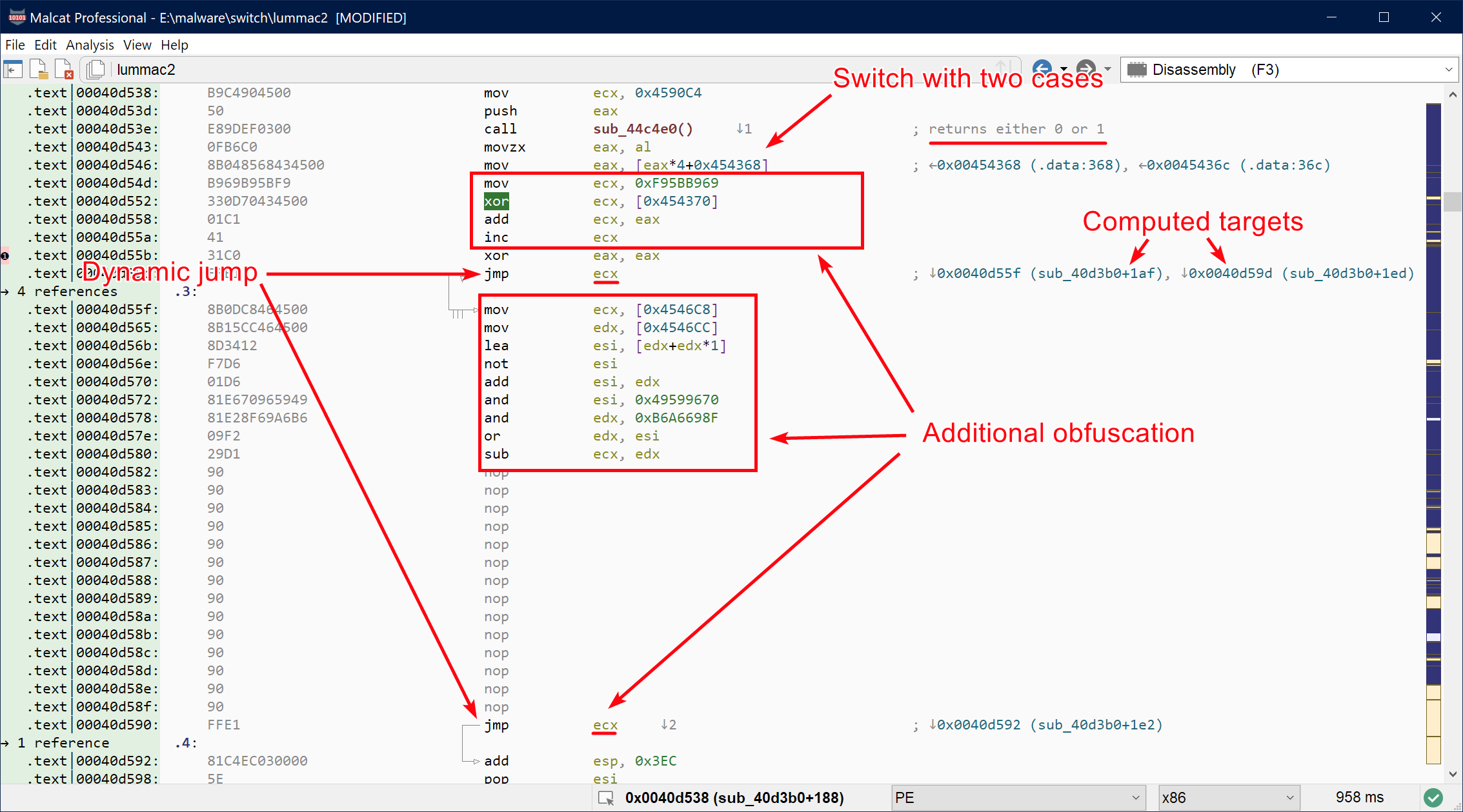
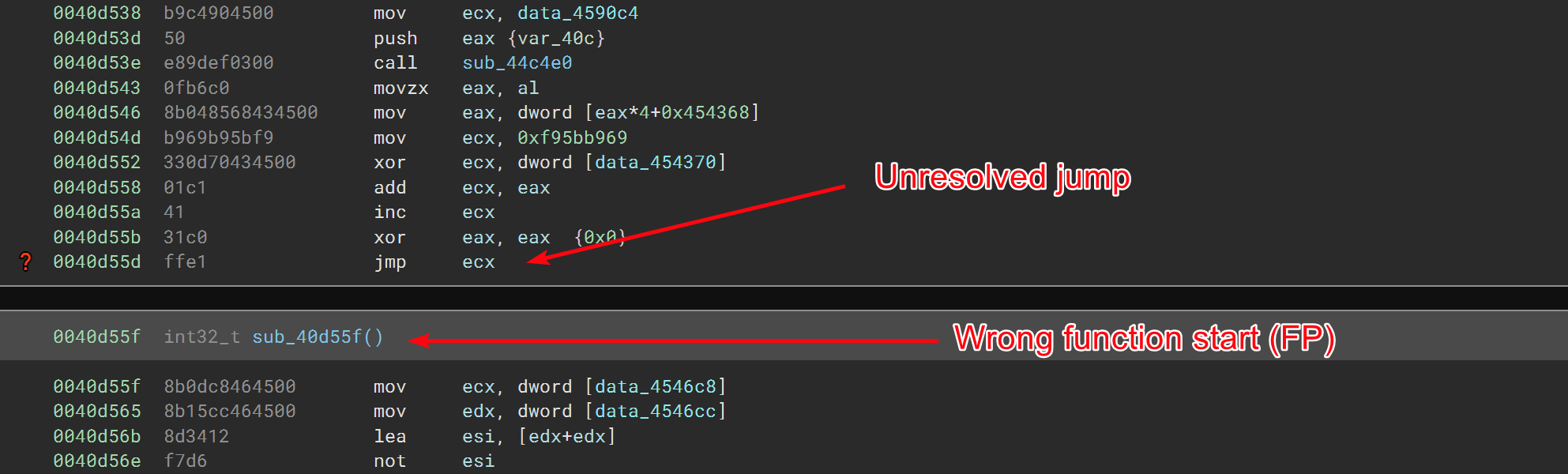
Problems arise when encountering dynamic jumps. Dynamic jumps are generated on a regular basis by compilers, by the C switch instruction for instance, or via C++ virtual calls. Some malware abuse them too in order to make static analysis harder. To solve these dynamic calls, the behavior of the program needs to be emulated, at least to some extent, in order to compute the target address. Malcat uses an abstract-interpretation-like analysis in order to over-approximate the value of CPU registers and stack values at any given program point. Not all instructions are emulated, only the ones the most likely to play a role in pointer arithmetic, such as add, mul, lea, and, etc.

Value of these registers and stack variables are overapproximated using a rather task-specific abstract domain: values are first approximated using a set of values (aka VSA analysis). When a set of values is getting too big, the abstract domain is switched to a masked interval, i.e. a min-max pair with a mask value. We have found out that this abstract representation gave good results for pointer arithmetic, while being relatively efficient to compute.
These two first phases (code identification and CFG reconstruction) are run multiple times, since the CFG reconstruction may discover new code entry points candidates. Malcat will stop once a fixpoint has been reached, i.e. when no new code location has been discovered.
Third phase: function boundaries
The last step in CFG reconstruction is identifying and delimiting functions inside the global CFG. Malcat's approach there is relatively simple, following loosely the technique described in the Nucleus paper. The idea there is to cut all call edges in the CFG and identify all connected components in the graph. Each connected component defines a function.
The simplicity of this algorithm as well as the non-reliance on pattern matching makes it not only accurate, but also compiler-agnostic. And these are good properties for Malcat, since we don't have the man-power to deal support many compiler specifics. But as always, the devil lies in the details, and the Nucleus function identification algorithm needs to address two major challenges:
- Identifying tail calls, where the compiler uses a
jmpinstruction instead of acallfor the last function call of a function. - Dealing with non-returning functions
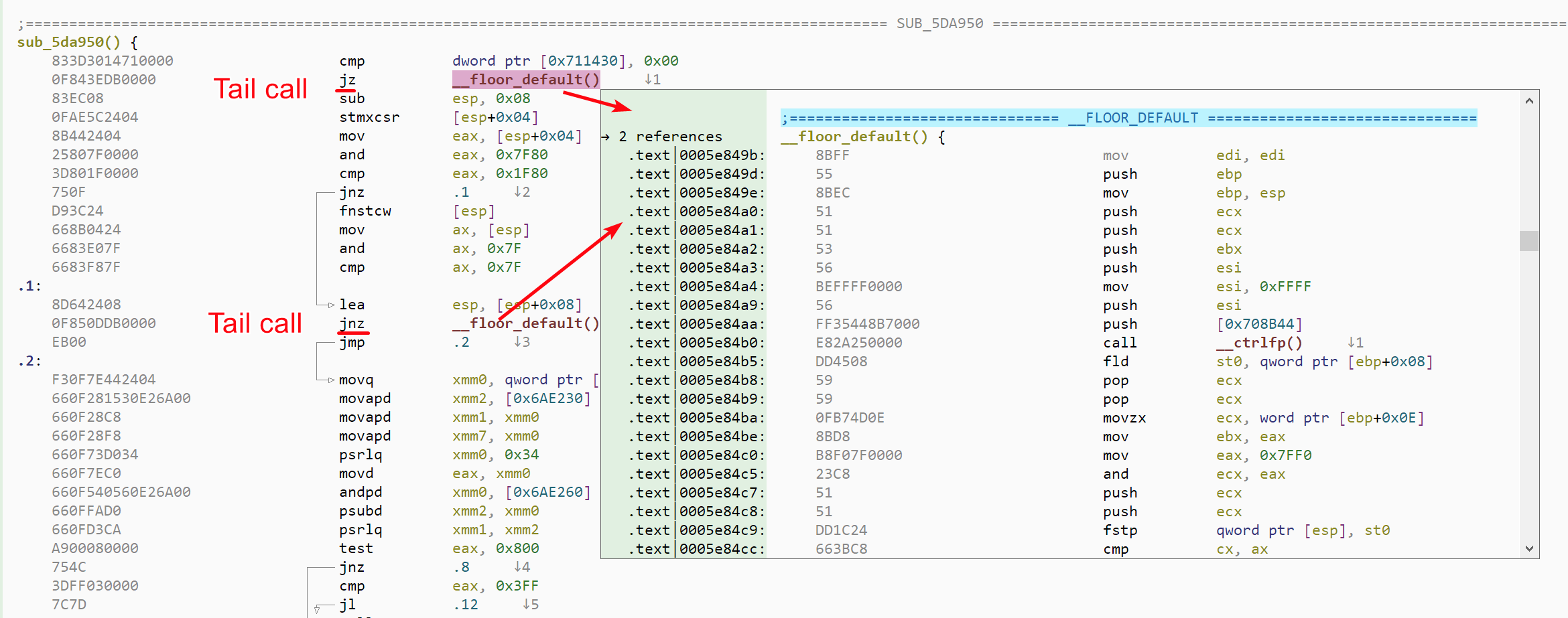
Malcat uses heuristics to solve both problems. While tail-call analysis in Malcat performs relatively well, as the results presented in the next chapter suggest, we are currently not very happy about our non-returning function identification algorithm. Some work still needs to be done there, such as building a large library of non-returning APIs. This is an area that we will improve further in the future.
How does Malcat perform?
Malcat's main target is and will always be malware analysis, and as such our goals diverge a bit from the big boys (i.e. ghidra, binja, ida & co). We want in priority:
- fast code analysis (malware triaging means looking at many programs per day)
- a sound CFG recovery algorithm, resilient to code obfuscation
- a good function boundaries identification for Kesakode
On the performances side, as you will see when you test the new release, the new abstract interpretation based analysis adds an overhead of about 10-15% of CPU time to the old CFG analysis present in Malcat. That's non-negligible, but you have to put it in perspective. Malcat's CFG analysis has always been very fast, or at least (a lot) faster than the other big RE solutions, so 15% is not a big deal at the end.
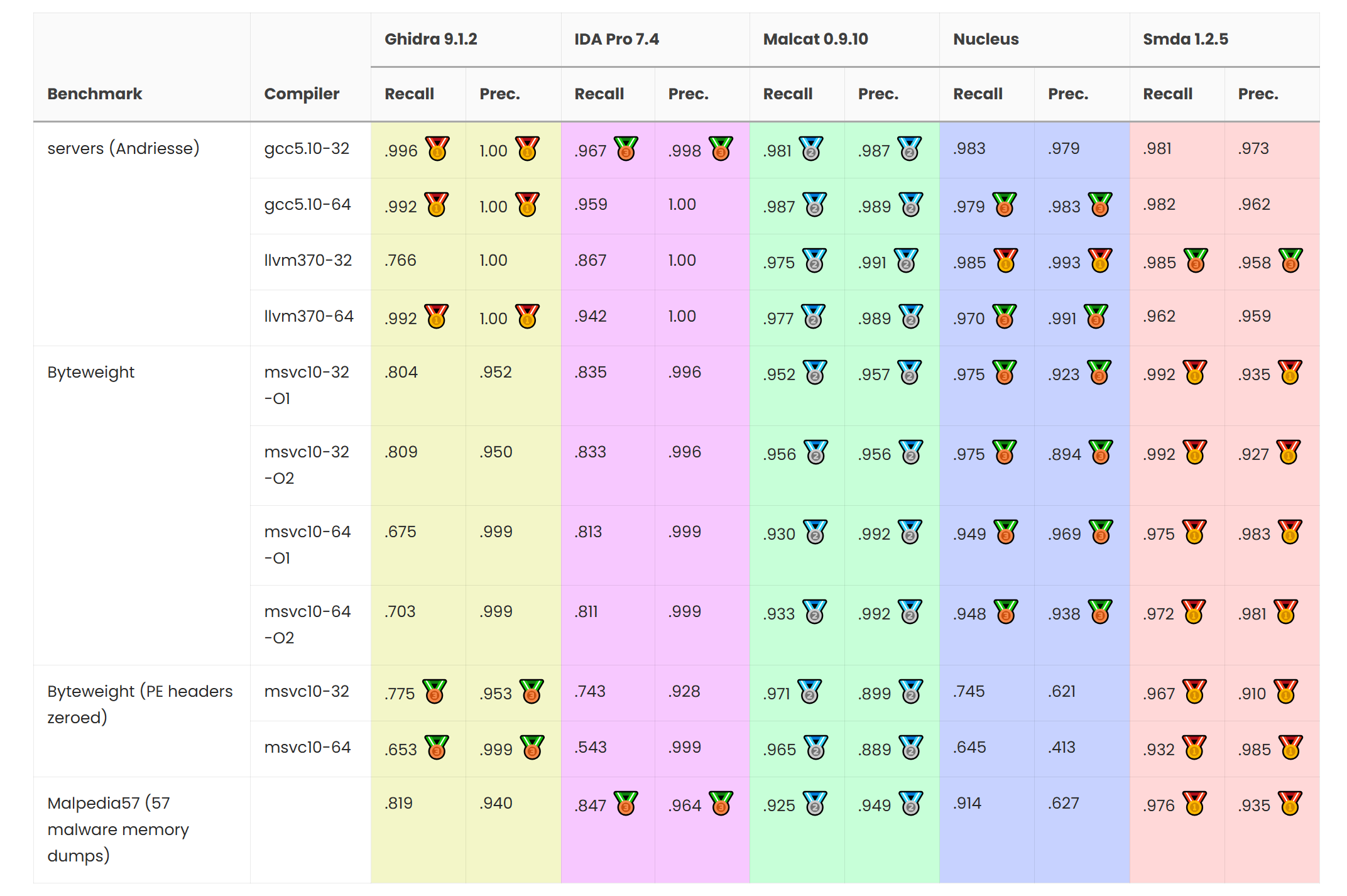
Regarding the soundness of our new code analysis, the best way to measure it is to test it against publicly available test sets. While there are many academic papers on this topic available online, we have chosen the work published in Dr. Daniel Johannes Plohmann's thesis (Malpedia's founder). In his thesis, he compares his own binary analysis framework (SMDA) against commercial solutions on your usual test sets (byteweight, SPEC-C) and, an original twist, on his own set of dumped malware images. Since malware analysts are looking at sandbox/process dumps on a regular basis, we figured this would make a good benchmark.
On page 128 of the thesis, you can find a function boundaries benchmark performed against the following solutions:
We have run Malcat's new CFG recovery algorithm against this test set1 (special thanks to D. Plohmann for giving us access to his Malpedia57 set!) and put all numbers inside the table below:
Note: recall is the percentage of functions rightfully discovered, i.e. how exhaustive is the analysis. A lower score means functions have been missed. Precision on the other hand is the ratio of good answers given, i.e how error-prone is the analysis. A lower score means non-functions have been identifed as functions.
| Benchmark | Compiler | Ghidra 9.1.2 | IDA Pro 7.4 | Malcat 0.9.10 | Nucleus | Smda 1.2.5 | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Recall | Prec. | Recall | Prec. | Recall | Prec. | Recall | Prec. | Recall | Prec. | ||
| servers (Andriesse) | gcc5.10-32 | .996 🥇 | 1.00 🥇 | .967 🥉 | .998 🥉 | .981 🥈 | .987 🥈 | .983 | .979 | .981 | .973 |
| gcc5.10-64 | .992 🥇 | 1.00 🥇 | .959 | 1.00 | .987 🥈 | .989 🥈 | .979 🥉 | .983 🥉 | .982 | .962 | |
| llvm370-32 | .766 | 1.00 | .867 | 1.00 | .975 🥈 | .991 🥈 | .985 🥇 | .993 🥇 | .985 🥉 | .958 🥉 | |
| llvm370-64 | .992 🥇 | 1.00 🥇 | .942 | 1.00 | .977 🥈 | .989 🥈 | .970 🥉 | .991 🥉 | .962 | .959 | |
| Byteweight | msvc10-32 -O1 | .804 | .952 | .835 | .996 | .952 🥈 | .957 🥈 | .975 🥉 | .923 🥉 | .992 🥇 | .935 🥇 |
| msvc10-32 -O2 | .809 | .950 | .833 | .996 | .956 🥈 | .956 🥈 | .975 🥉 | .894 🥉 | .992 🥇 | .927 🥇 | |
| msvc10-64 -O1 | .675 | .999 | .813 | .999 | .930 🥈 | .992 🥈 | .949 🥉 | .969 🥉 | .975 🥇 | .983 🥇 | |
| msvc10-64 -O2 | .703 | .999 | .811 | .999 | .933 🥈 | .992 🥈 | .948 🥉 | .938 🥉 | .972 🥇 | .981 🥇 | |
| Byteweight (PE headers zeroed) | msvc10-32 | .775 🥉 | .953 🥉 | .743 | .928 | .971 🥈 | .899 🥈 | .745 | .621 | .967 🥇 | .910 🥇 |
| msvc10-64 | .653 🥉 | .999 🥉 | .543 | .999 | .965 🥈 | .889 🥈 | .645 | .413 | .932 🥇 | .985 🥇 | |
| Malpedia57 (57 malware memory dumps) | .819 | .940 | .847 🥉 | .964 🥉 | .925 🥈 | .949 🥈 | .914 | .627 | .976 🥇 | .935 🥇 | |
At the end, we are pretty happy with these results, especially if you keep in mind that Malcat's focus doesn't lie in its code analysis. Sure, Malcat does not get many gold medals, but it is consistently second for all test sets. More importantly, Malcat's function identification performances (as well as SMDA's) do not degrade significantly when facing memory dumps and/or trashed PE files. This means Malcat should behave properly in face of obfuscated programs too, which is pretty important for our users! This is most likely due to the use of Markov chains and the very little reliance on pattern matching inside Malcat.
Note that the results shown above should be interpreted with great care. First, function boundaries detection is only a small part of what a reverse engineering software does. While it is important (especially for Kesakode), stack analysis or type propagation (which are notably absent in Malcat) have a bigger impact for deep RE sessions.
Second, the extent of these tests is limited: they only cover x86 software, and you won't see any fancy compilers (I would be curious to see these tests performed on Delphi programs for instance :).
Third, they don't take every performance criterions into account, such as memory or CPU usage, which are also important. For instance IDA has relatively low memory consumption, which is great for the analysis of big programs, while Nucleus/Binary Ninja has some room for improvement in this domain. On the contrary, Malcat is the fastest of all these software by a large margin (even if we consider all of Malcat's additional analyses), while SMDA, being written in python, is most likely the slowest.
Finally, not all major reversing software are present: Radare is missing and Binary Ninja, while having similiarities with Nucleus, is likely to get better scores than Nucleus. And the software which are present are a bit outdated too now (IDA 9 is now out, as well as Ghidra 11.3). So even if this is a good becnhmark for malware analysis, take these scores with a grain of salt.
New architecture: MIPS
We usually divide CPU architectures in two groups:
- CISC: complex CPU architectures featuring numerous variable-width opcodes, e.g. x86
- RISC: CPUs with reduced instruction sets, each instruction being usually encoded on either 16 or 32 bits
While RISC architectures have a lot of advantages, the limited size of their instruction encoding make it usually impossible to load large immediates in a single instruction. The immediate needs to be assembled and/or computed across multiple instructions instead. This is particularly visible for addresses/pointers: you won't see any absolute address in the operands of a RISC program. Even for control flow instruction, most long-range jumps and calls need to compute their target dynamically using pointer arithmetic.
For these architectures, disassemblers have to perform at least some basic form of emulation in order to resolve jump and calls targets. But good news, Malcat now features an abstract interpretation based analysis able to overestimate register and stack values. Helped by the newly-integrated capstone disassembly engine, we are now able to handle RISC architectures!

Since adding a new architecture is always a big change, we will start with baby steps and start with one of the simplest RISC architecture: MIPS. The MIPS architectures is used in embedded systems, video game consoles (like the PS1/PS2) and network devices. We have added support to two MIPS flavors: MIPS32 and MIPS64, both of them in either their LSB or MSB variant. You will be able to not only disassemble MIPS programs, but also decompile them, courtesy of Malcat's integration of the Sleigh decompiler.
Since our database for MIPS program is ultimately non-existent, Kesakode results will be limited to strings for MIPS programs. But all other features for Malcat should work as expected.
Decompiler
Sleigh update
Malcat embeds internally the Sleigh decompiler, the same decompiler you can find in Ghidra. In this new release, we had to update the Sleigh decompiler in order to add support for the MIPS architecture. We have used this opportunity to update the Sleigh decompiler to its latest version, syncing with Ghidra 11.3.1. This update was long overdue and required a non-negligible amount of effort to adapt to the numerous changes introduced over the last 2 years. Nonetheless, here it is! Having a good engine to decompile the occasional decryption function is rather nice to have imho.
A nice side-effect of this update is that Malcat has now also access to Sleigh's emulation capabilities. So who knows, in the future you may see it put to use inside Malcat.
Variables renaming
You have now the possibility to rename variables from within the decompiler view. Just right-click any local variable or function parameter and chose Rename variable in the context menu. The renaming can be undone/redone and is saved within the Malcat's project file.
Like for function/global variable renaming, you can also popup the rename dialog by hovering you mouse over the variable and hitting N.
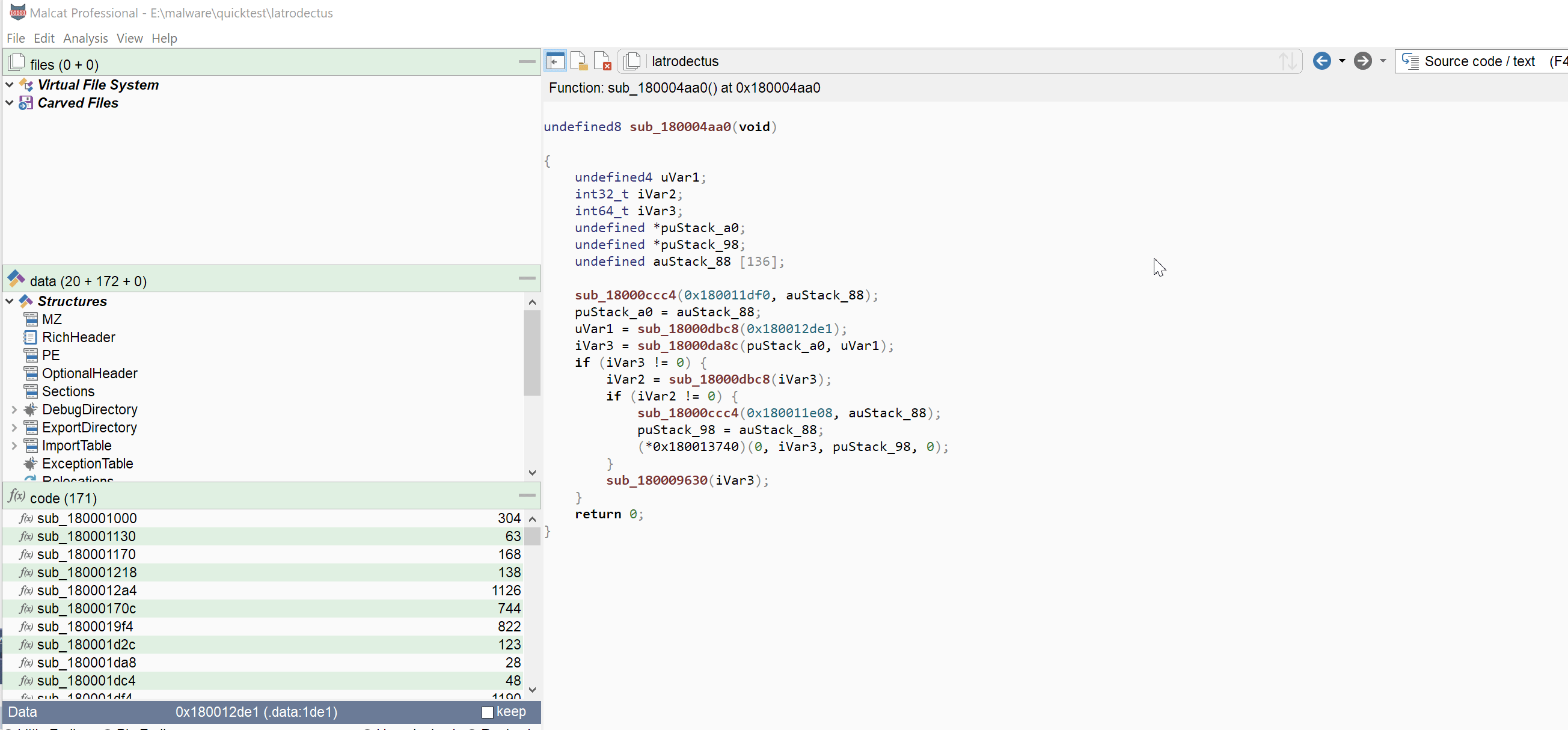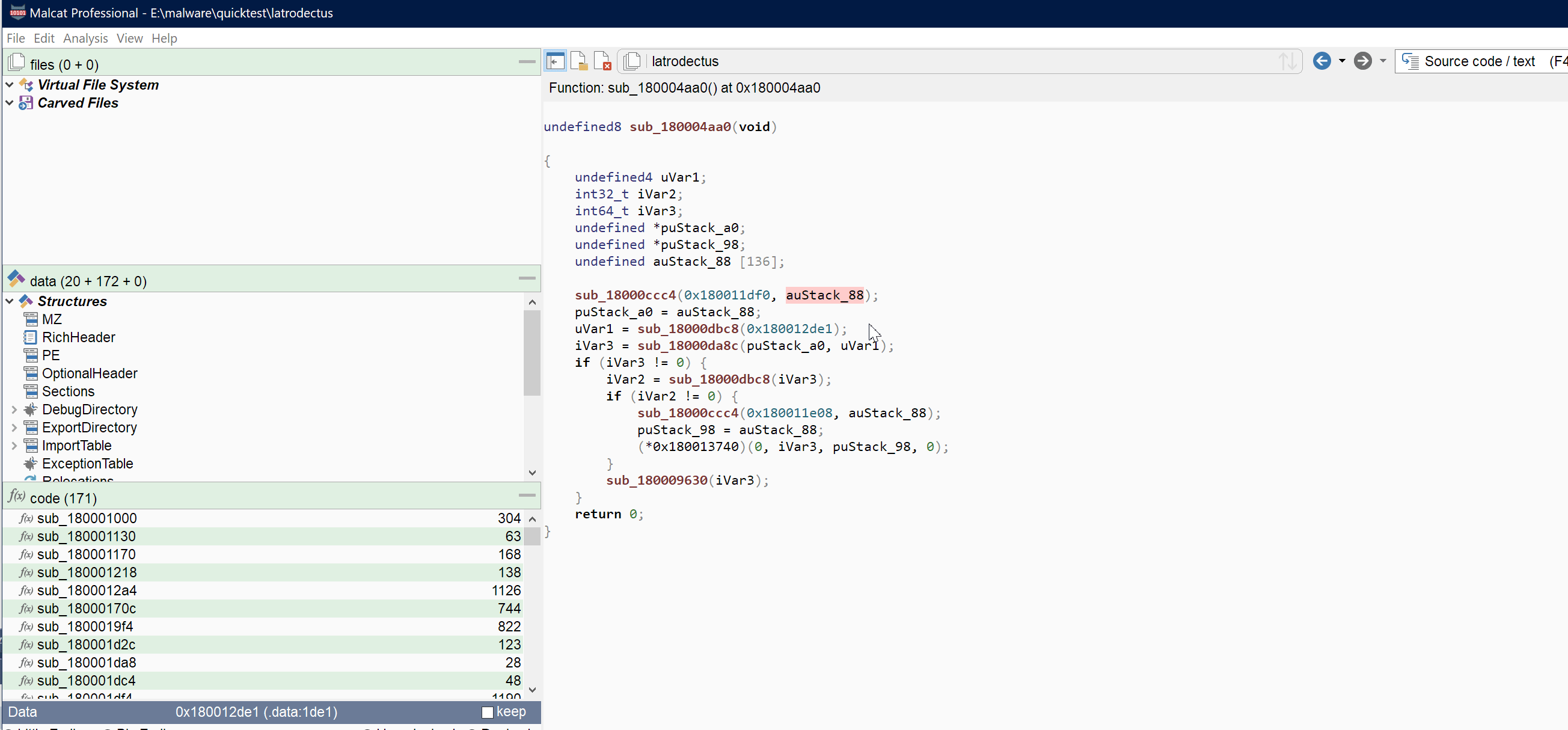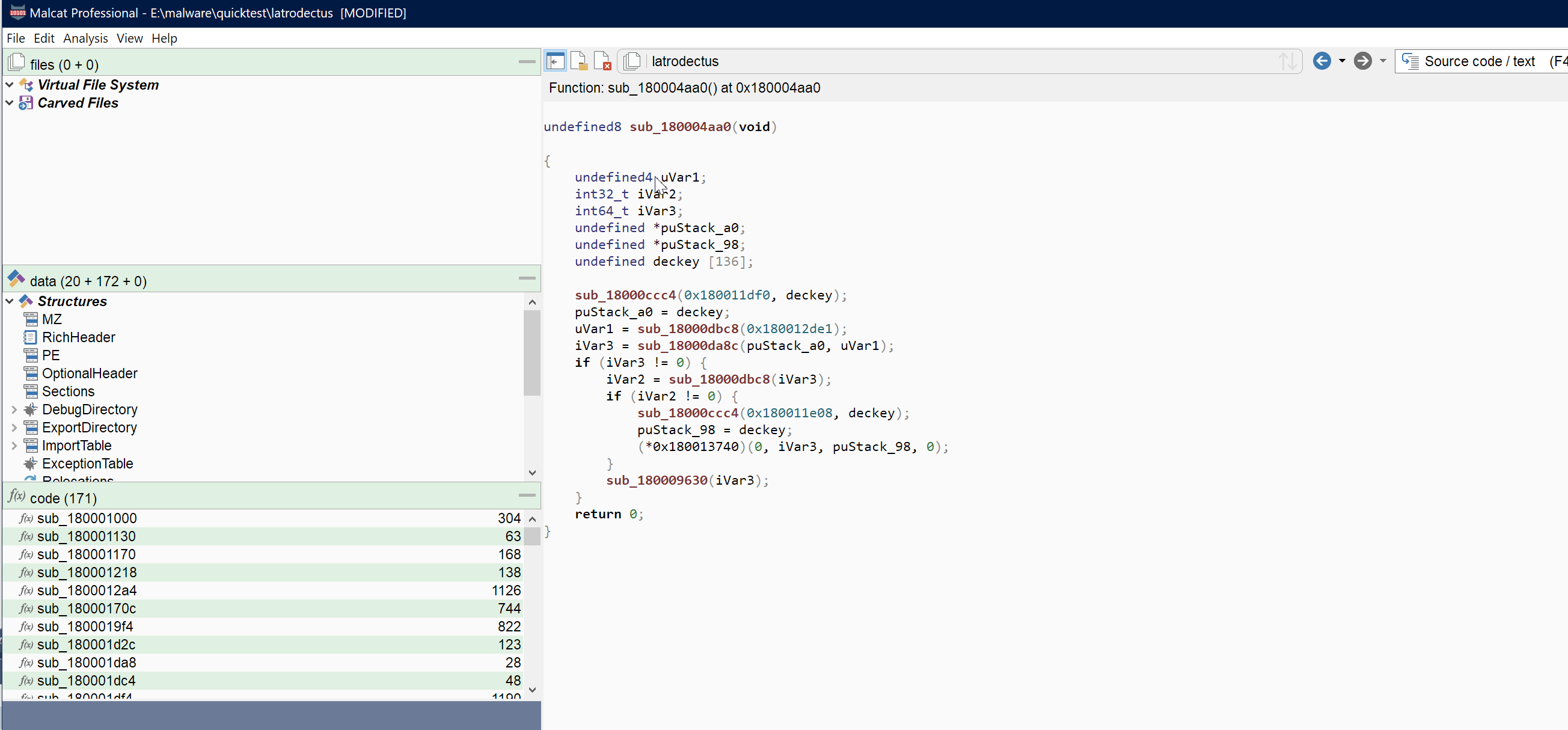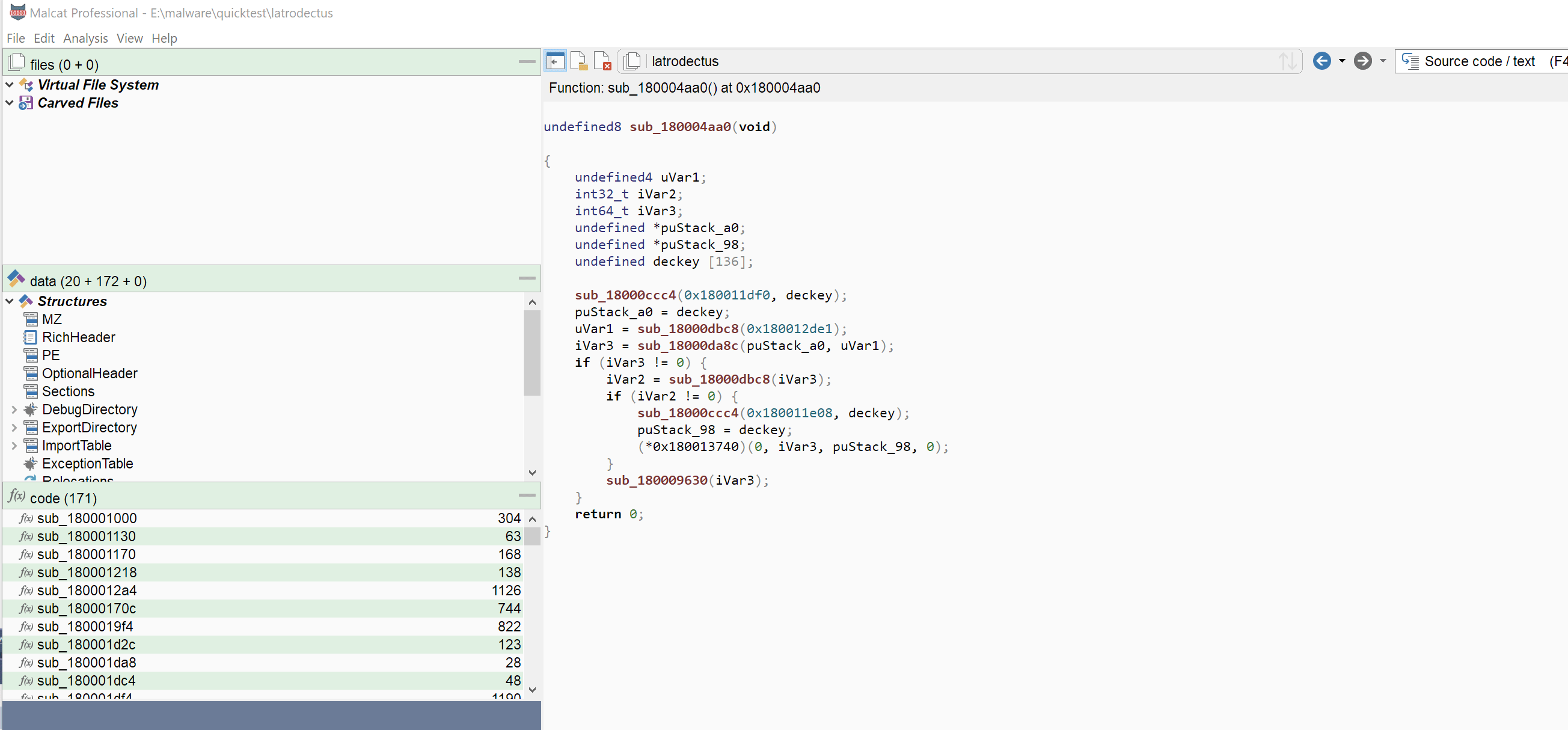
This is a feature which was requested by some of you. Now that doesn't make Malcat's decompiler view a replacement for Ghidra obviously, but it may help you reversing some simple functions.
Other quality of life improvements
Code / data preview
We have made an effort to make the interaction between the mouse cursor and displayed addresses more coherent across Malcat's different views. Before the update, hovering over an address in any text-based view would either display a preview of what is located at the address in the quickview windows (bottom left) or a list of cross references pointing to this address.
Since some of you were a bit confused by this part of the UI, we have changed the behavior to be more similar to IDA or Binary Ninja:
- Hovering quickly over an address displays cross-references in the quickview (can be disabled in the options on a per-view basic)
- Hovering for a second over an address displays a data preview in a popup (only if the address is physically backed)
- Pure virtual addresses cannot be clicked anymore (before, you would jump to the nearest physically-backed address)
In practice, this will look like this:
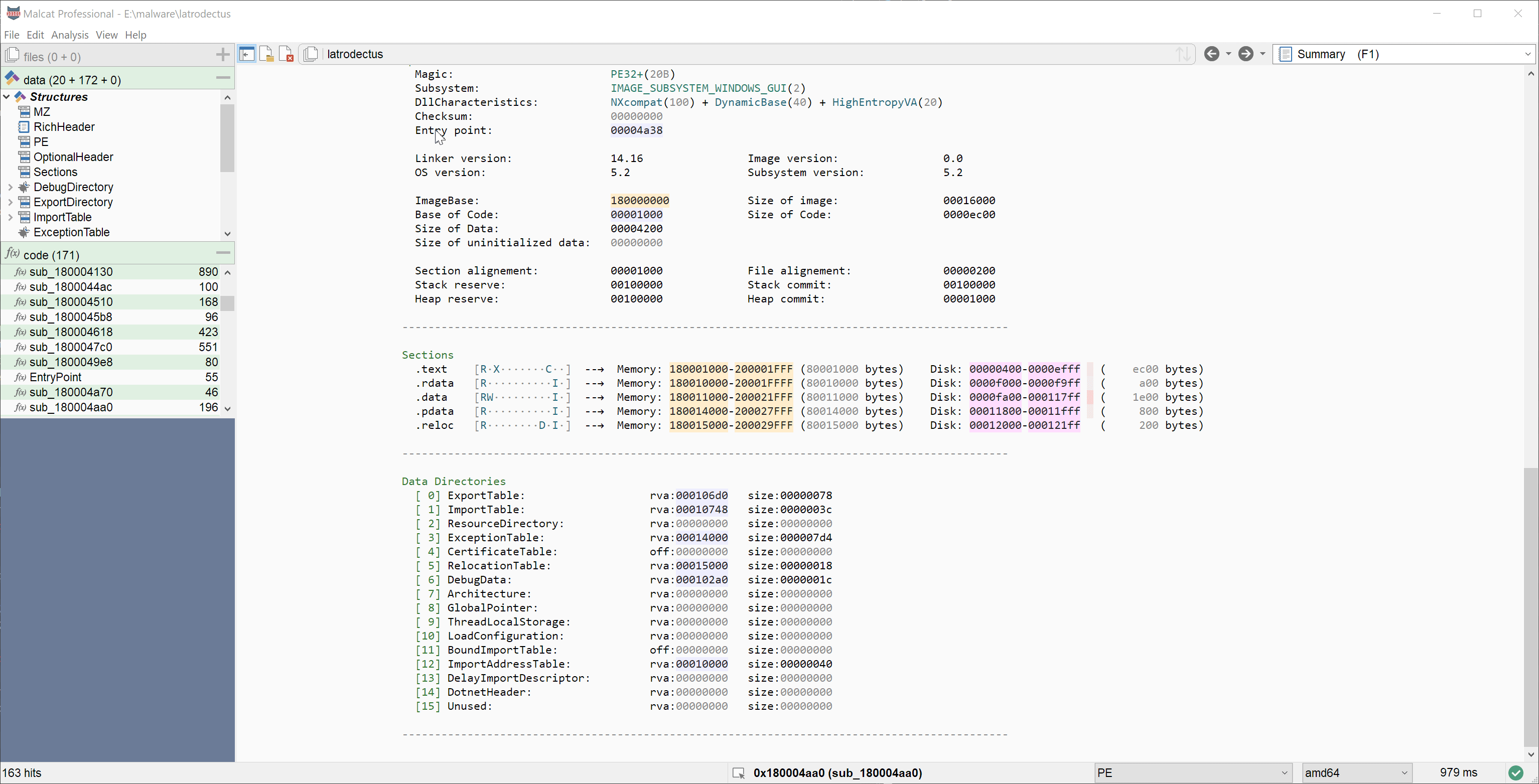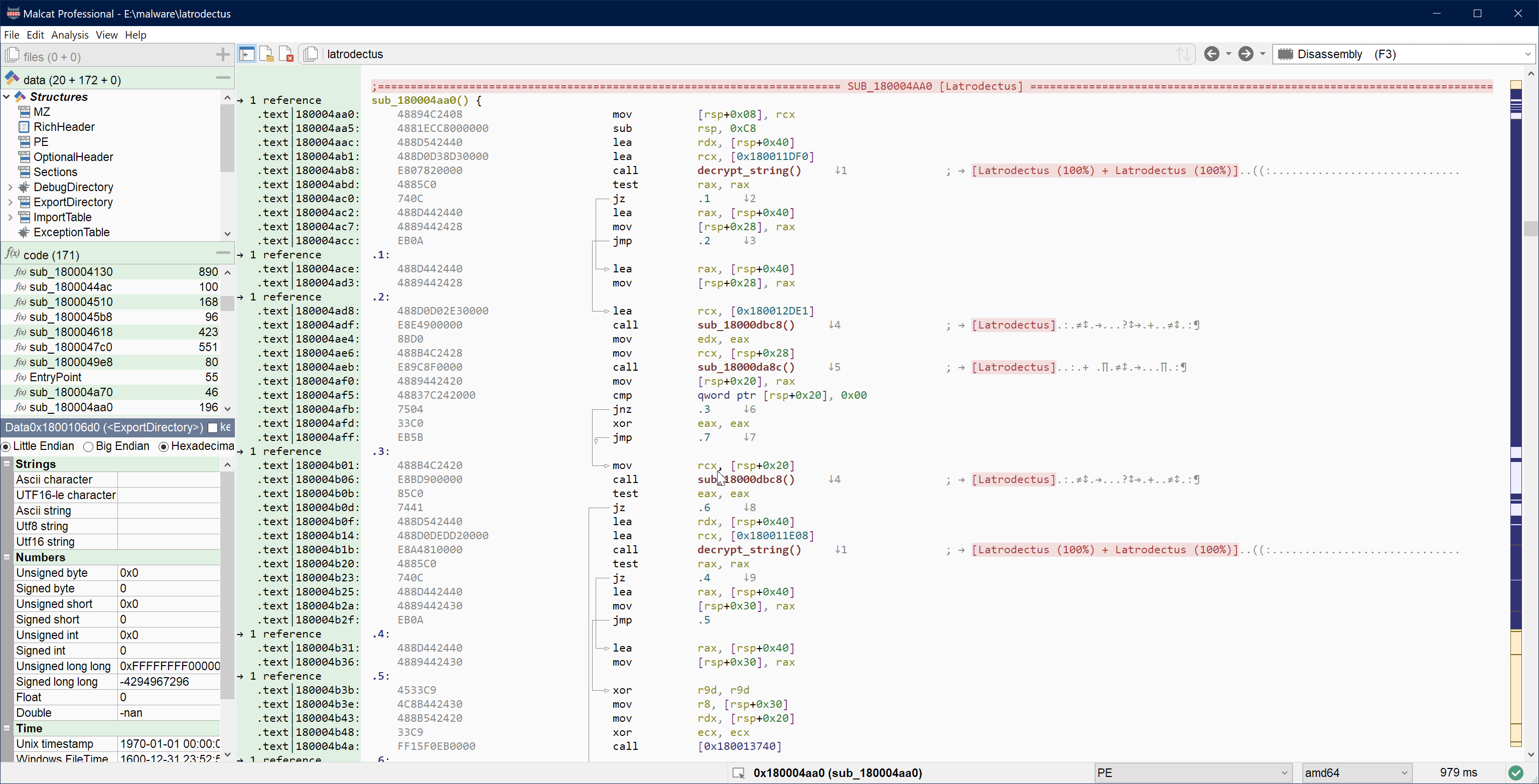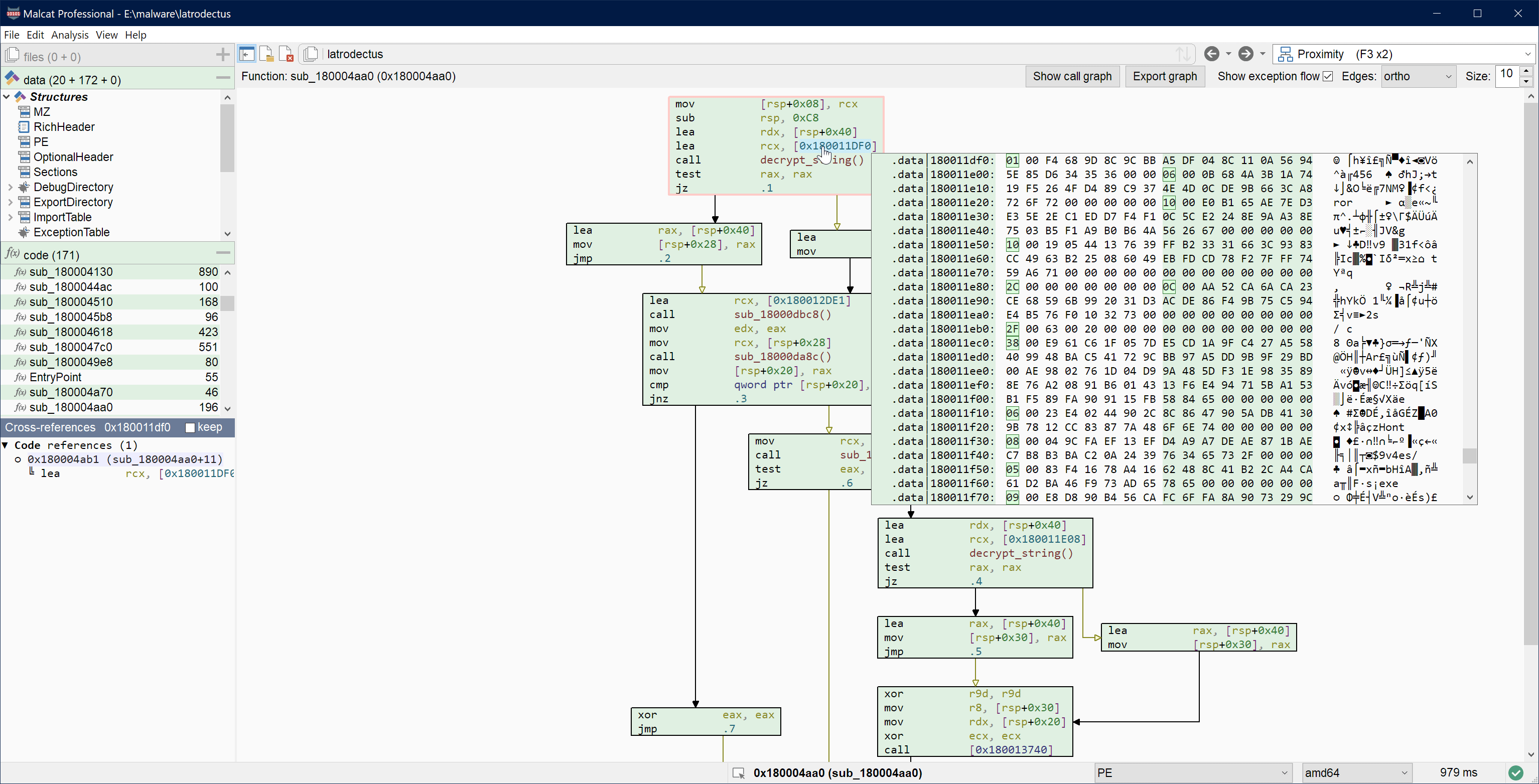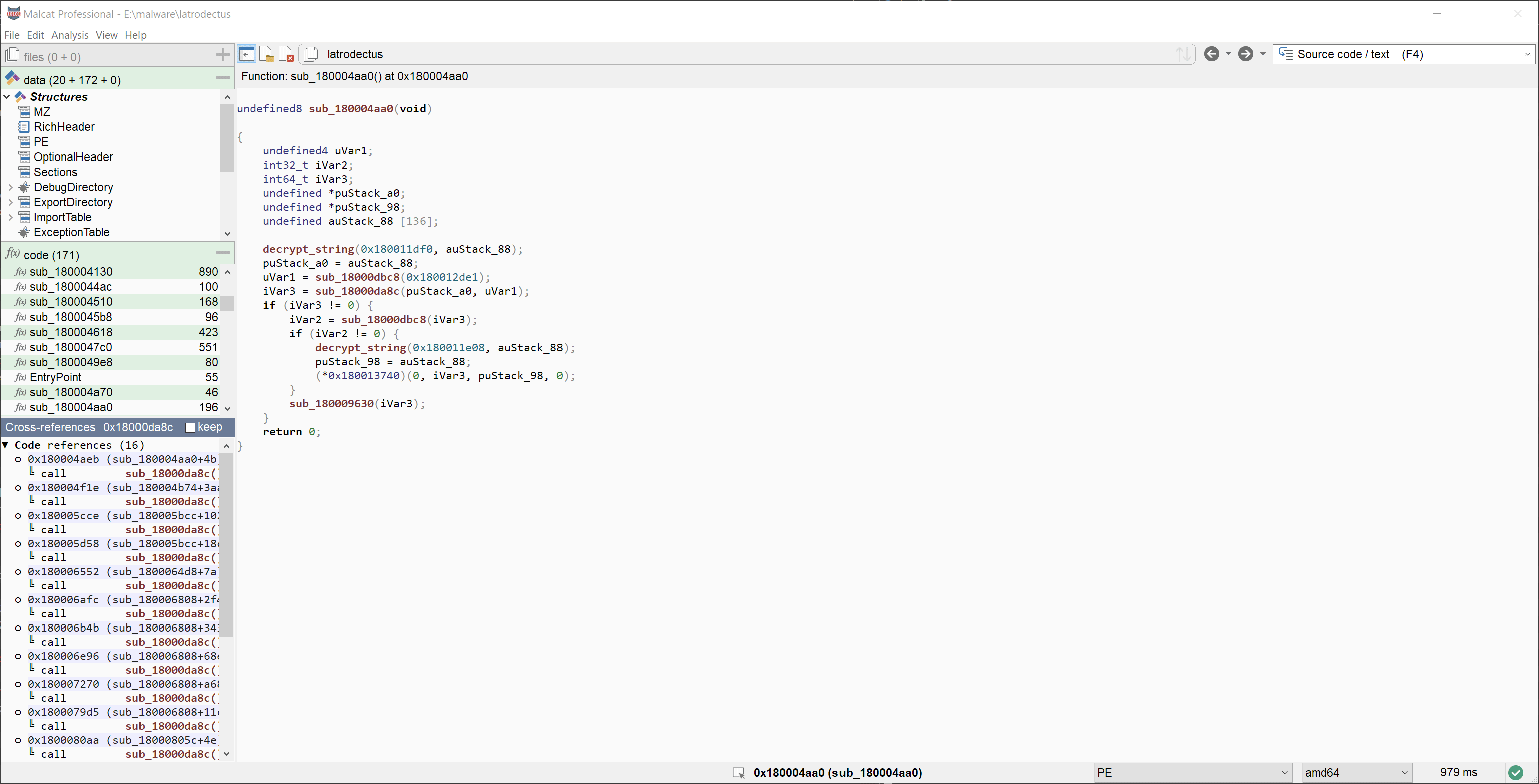
UI choices will always be a matter of taste, but we think that adhering to the standard set by older tools is a step in the right direction.
Visual matching of registers / constants
Another improvement made to the disassembly, proximity and decompiler views is the highlighting of matching registers, variables and numbers. If you let your mouse cursor over a number or a register/variable, Malcat will highlight all the other instance of this element in the current view. This is particularly useful to look for register or local variable definitions in a disassembly or C listing.
Corpus search
As a malware analyst or detection engineer, you often need to search for a pattern or yara-scan a large number of files in a timely manner. Some of the most frequent use cases are:
- threat attribution: look for samples sharing a piece of code, a string or a Yara rule with the current file
- false positive remediation: look if the selected string is a good candidate for your new Yara rule by searching in your clean files set
- malware analysis: want to compare the current analyzed malware against previous versions? Search your corpus for all previous samples of the current family (using a Yara rule for instance)
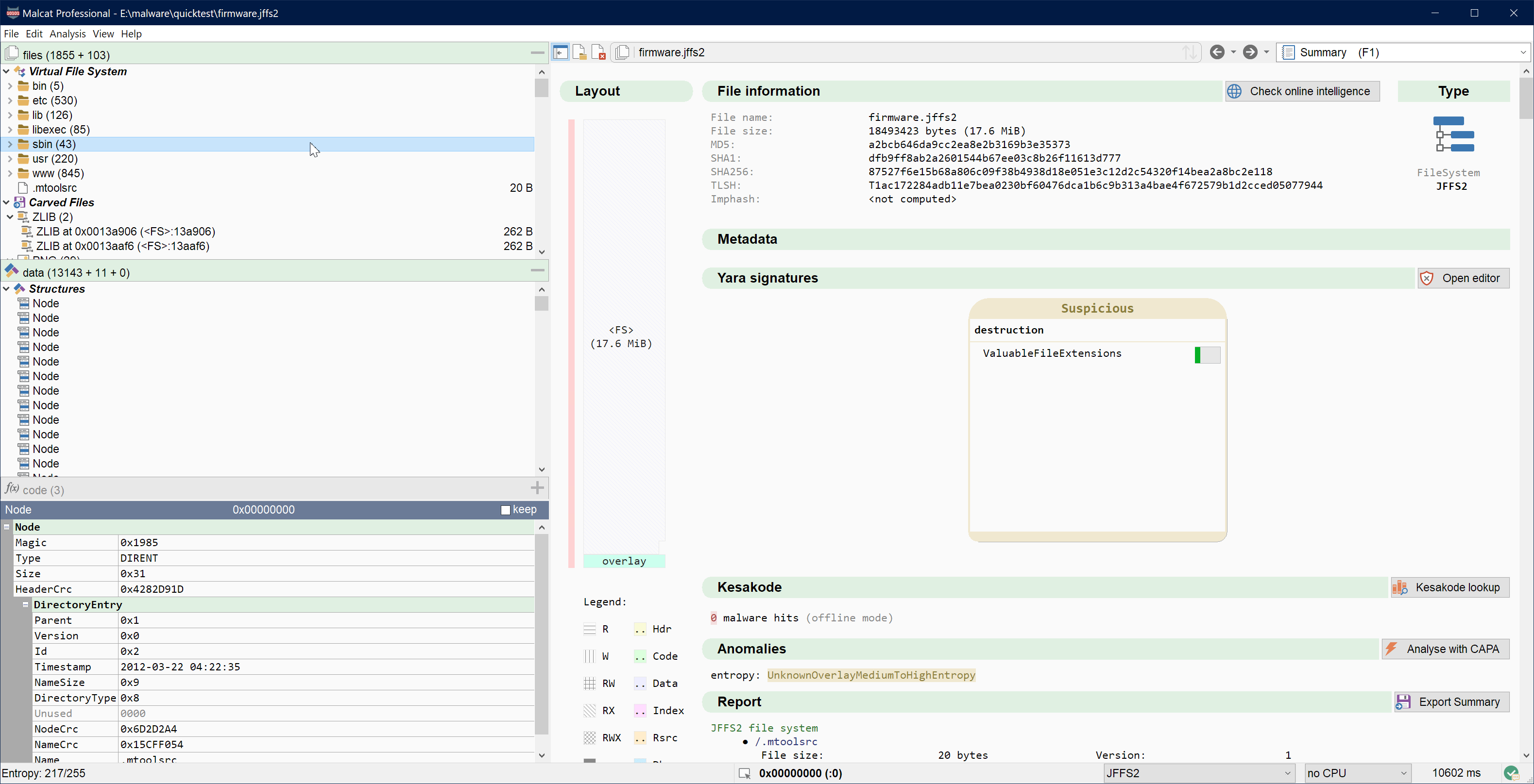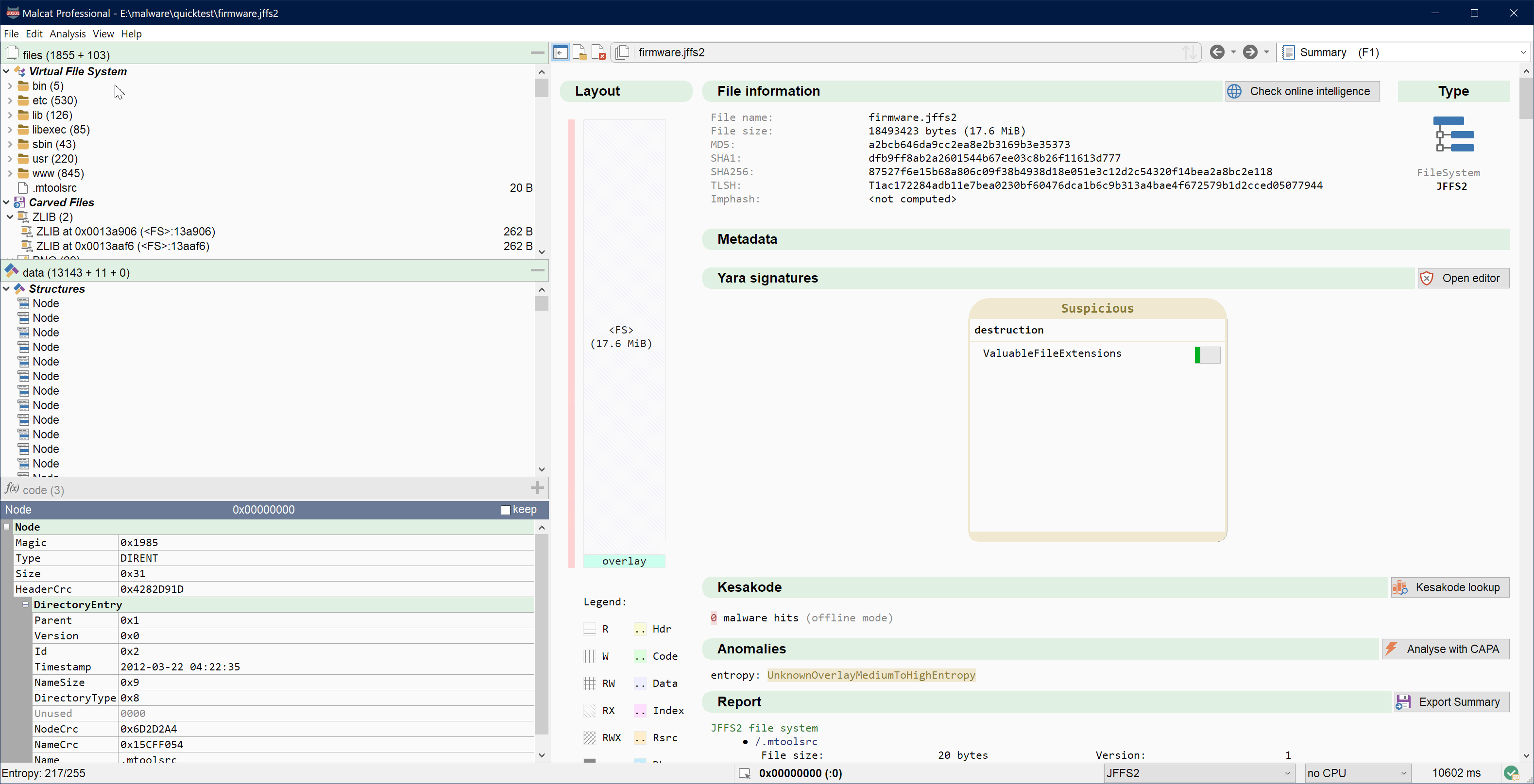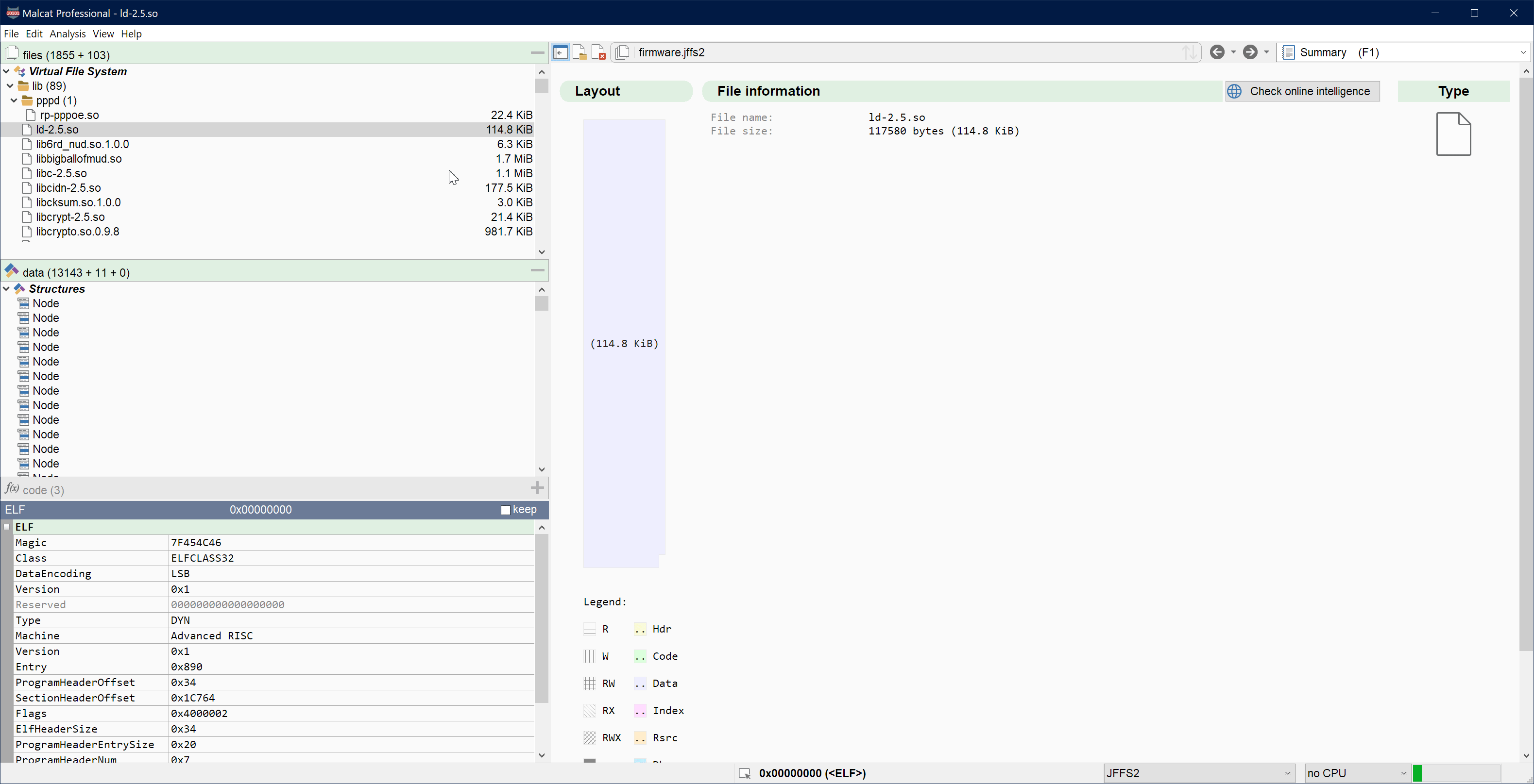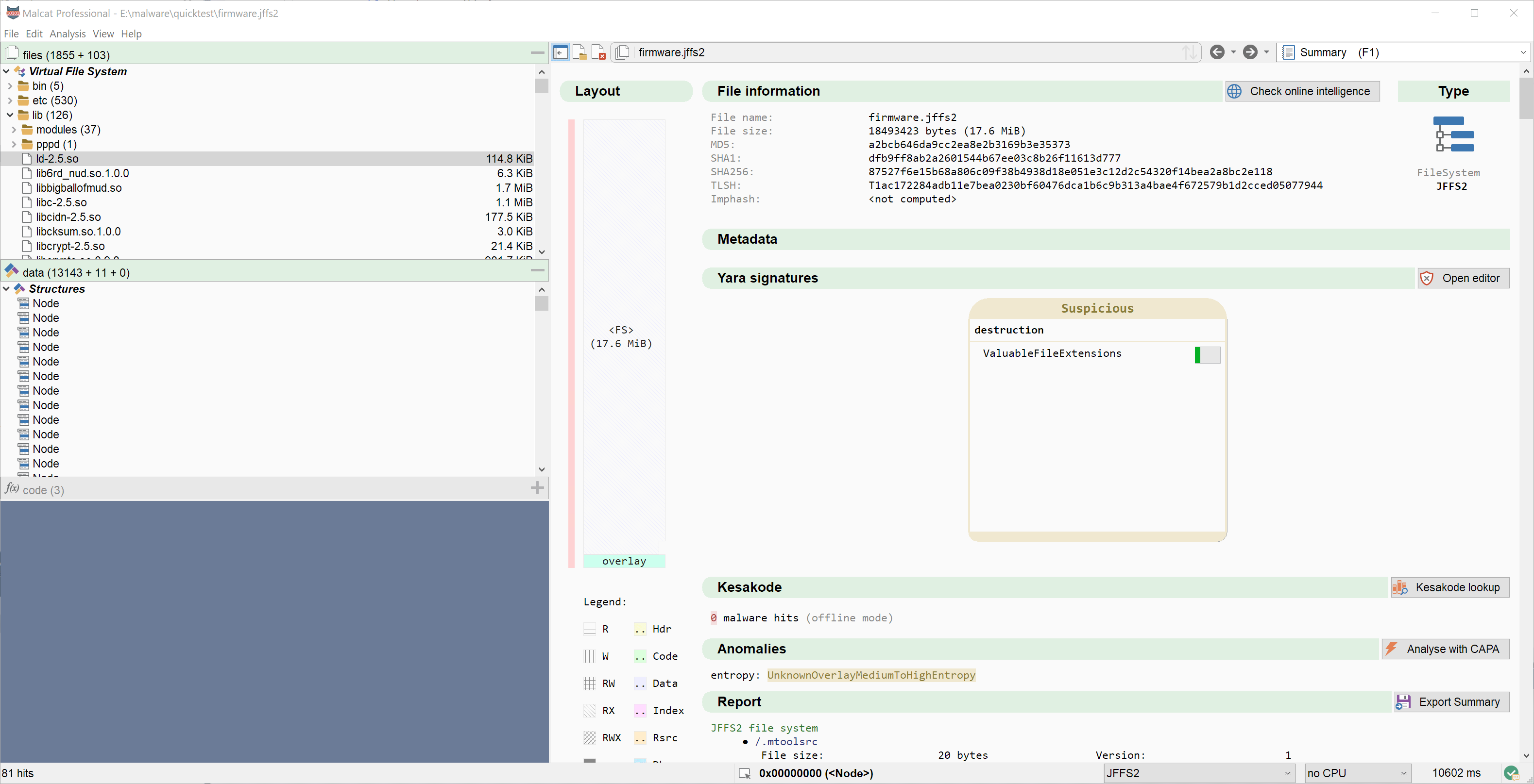
The full and pro Malcat versions already allow you to look for a pattern, string or Yara rule in a corpus of files defined previously. In 0.9.10, we have improved this workflow a bit. Searching in your corpus (now called "Searching in other files") now lets you select which directories you want to use for your search (you may not want to scan all your files every time after all). Another addition, you can now also search for a pattern in all files currently open in Malcat! This should come handy when you are creating a rule for several samples at once. See it in action:
Another change in the corpus search functionnality: we have removed the VirusTotal VTGrep search feature. The reason is simple: this feature was sadly not compatible with VTGrep's latest API changes. VirusTotal gave us a 1-month limited API key a few years ago for the integration and it is long expired, meaning we can't maintain it anymore.
In a future release, we will open the corpus search and let users define their own search engine in python, in a similar fashion to what we did with kesakode. Maybe someone with an API key will then be able to rewrite the VTGrep integration then.
Files quickfilter
Malcat can open more than 50 file formats and extract and navigate through embedded files. Sometimes, in particular for file systems and large archives, the number of identified files can be huge, making browsing and searching through them a pain. In Malcat 0.9.10 you will be happy to find a quick-filter control in the files panel: just start to type part of a file name there and the file view will be filtered.
If you have other features request, don't hesitate to hop on our Discord server and tell us about it. We take every feedback seriously!
Changelog
There have been several smaller quality of life improvements and bug fixes made to Malcat in this release. If you want the complete list, have a look at the changelog:
● Disassembler:
- Refactoring of the CFG recovery algorithm
- Vastely improved dynamic pointer recovery during CFG reconstruction
- Added support for MIPS32 CPU
- Added support for MIPS64 CPU
- Added new gap analysis in the CFG reconstruction (but only when markov heuristic is on)
- Disassembly view: hovering a second over a register/number highlights all registers/numbers with the (exact) same text
- Added documentation for Malcat's CFG recovery algorithm
● Decompiler:
- Updated sleigh decompiler to the version used in Ghidra 11.3.1
- Added support for MIPS32 CPU via sleigh
- Added support for MIPS64 CPU via sleigh
- Decompiler view: hovering a second over a variable highlights all instances of this variable
- Decompiler view: you can now rename variables the same way you could rename function and global adresses. The new names are also saved with the project.
- Decompiler view: you can now view and edit user comments
● Strings:
- Improved Rust strings recovery heuristics
● Transforms:
- Added "zstd compress" and "zstd decompress" transforms
- Added "rc2 decrypt" and "rc2 encrypt" transforms
- Added ctr mode for aes
- The transform dialog now automatically populates a base64/hex decode transform for base64/hex-encoded strings
● Corpus search:
- Removed vtgrep search (I sadly don't have a VTI API anymore to maintain it)
- Searching in corpus now popups a dialog to let you select where to search
- Corpus search now allows you to search in all currently open files too
● Scripting:
- Added Latrodectus string/config decryptor
- Added new method analysis.strings.filter() for native-performance filtering
- Added malcat.pyi file for better autocompletion of malcat scripts using external editors
- Improved malcat.kesakode.py cli script output in recursive mode
● Anomalies:
- Improved performance of strings anomalies when facing large amount strings
● User interface:
-The interaction between the mouse cursor and addresses is now more consistent across views:
* Hovering quickly over an address displays cross-references in the quickview (can be disabled in the options on a per-view basic)
* Hovering for a second over an address displays a data preview in a popup (only if the address is physically backed)
* Pure virtual addresses cannot be clicked anymore (before, you would jump to the nearest physically-backed address)
- Added a quick filter in the files panel
- Changed call graph view shortcut to F5 x2 to avoid involontary display when switching to the more used summary view
- The DNA view is now disabled by default, can be reactivated in the options
- jumping between functions from within the functions panel now stays in the decompiler view if needed
- Added Alt-Left and Alt-Right as shortcuts for goto prev/next location
- Redesigned the "download by hash" dialog. Will now also accept a local path of a file to open.
- Copy word/qword context menu actions now respect the endianneness of the file
- Added copy qword context menu action
- Improved view-switching performance by ~20%
● Parsers:
- [WINDOWS] py7zr is now packaged in the embedded python interpreter, meaning 7z archive unpacking is now available by default
- Added support for Gzip compression in the SquashFS parser
- Added support for InnoSetup 6.4.0 and 6.4.0.1
● Bug fixing:
- [ZIP] Fixed bad parsing of zip files having their zip64 header sizes set to 0
- [ZIP] Improved DataDescriptor localisation code
- Right click on selected instructions in disassembly view when the selection was made using something other than mouse movements would display the instruction context menu instead of the selection context menu
- Config options would not be properly forwarded to 3rd party kesakode providers if called before any intelligence provider
- Intelligence providers defined in user data dir would not override identically-named providers in malcat's data dir, the two versions would coexist instead
- The icon size in the projet switcher in Linux was too small
- The decompiler theme colors would be wrongly displayed in the options dialog (but changing them still worked)
- Golang parser can now recover when TextStart member of the pclnheader has been zeroed
- Fixed a slowdown in the string view when displaying very large binary dynamic strings
-
minus the SPEC-2006 C/C++ test set which is sadly not available anymore :( ↩