
Some context
Why?
When I started programming, my first (Turbo Basic, yes) program was a conversational agent: a simple text loop with around 50 if-else branches. It felt alive and magical, and I've always kept a fascination for artificial chat programs since then. Now fast forward 30 years: with the recent improvements in large language models, I can somewhat feel again the excitement and awe of 9-year-old me.
So you can easily imagine that since the release of Malcat's MCP server I've played a lot with LLMs, analysing all sorts of malicious files, both for work and for fun. And I am still fascinated to observe LLMs in real time, correlating Malcat detections, following references to interesting strings, decompiling functions and just looking alive. In order to streamline the whole process, I have developed a malware triage pipeline that looks somewhat like this:
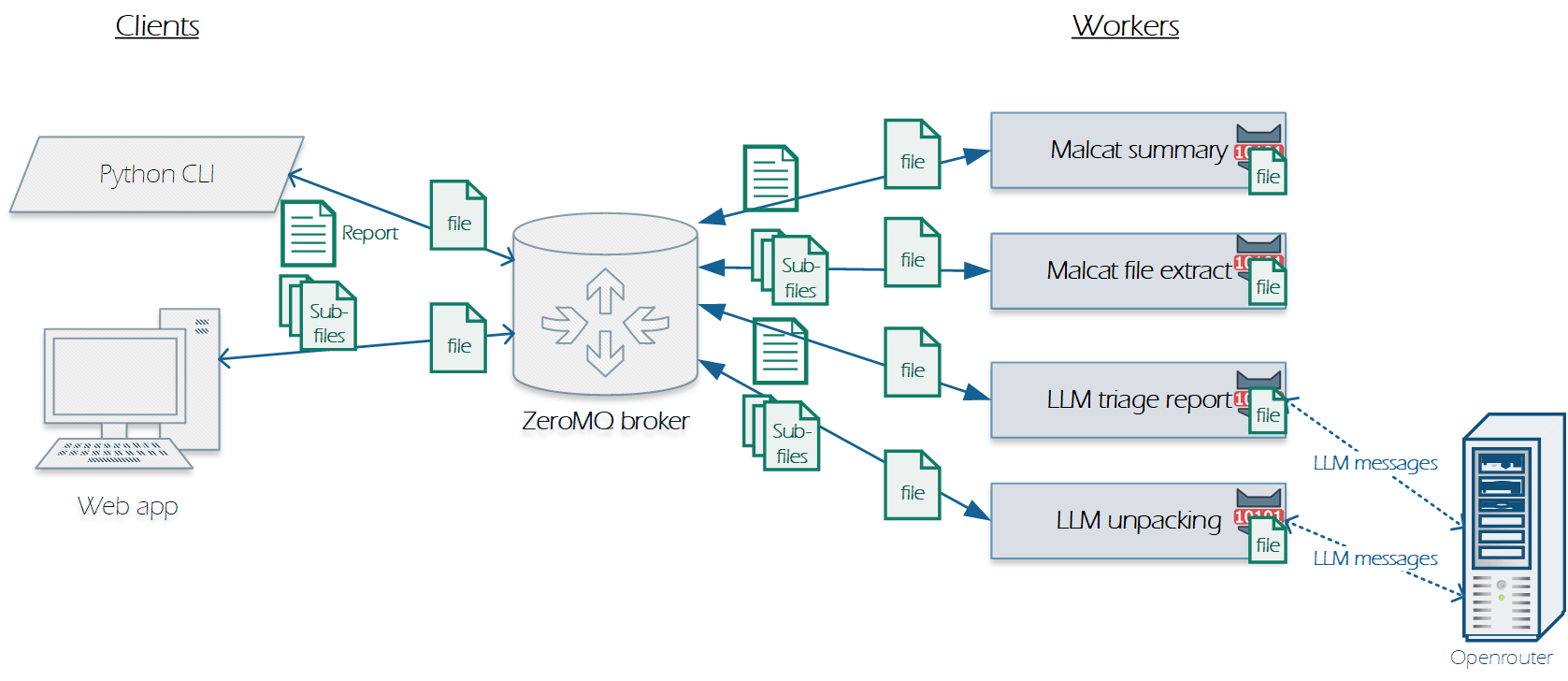
It all works wonders, but there is one question that was bothering me: which model should I use in my pipeline? All models are good (especially compared to my first BASIC program :) but I would like to know which one is best suited for malware analysis, and if possible, one that is relatively cheap. Of course there are metrics (cost per token, number of parameters) and benchmarks (SWE, HumanEval, etc.). But they don't tell the whole story, and they don't always apply to malware analysis (which is pretty input-token heavy and needs some ground truth knowledge).

So the obvious solution I came up with is to just put them to the test and see which model will win. In other words, a good old jousting tournament :) The models still standing at the end of the fight shall have the glorious honor of working in my pipeline. And since the results of this test could potentially apply to other people and other scenarios, I've decided to publish the results here.
NB: Don't expect a very scientific benchmark. It's just me testing a bunch of LLMs on my use case.
TL;DR: If you are in a hurry, you can jump to the result of the triage benchmark here and the result for the static unpacking benchmark here, or read directly my conclusion.
The rules 📜
Every tournament needs a set of rules. Otherwise it's just a brawl. So here are the rules of our competition:
- In Malcat we trust: Models only have access to Malcat's MCP server.
- Thou shalt not compact: We want to harness the raw power of the model, so we'll abstract away some features you might find in OpenCode or Codex, like context compacting.
- Thou shalt remember a lot: We want big context windows, because disassembly/C listings are huge. So models with context windows under 1M tokens won't enter. Like for the roller-coaster.
- Thou shalt not lie: Negative points will be awarded for hallucinations.
- Concision is key: Models will have a total token limit. When this limit has been reached, they get a last message to output the result. Why the limit? Well, I'm not made of money. Also nobody wants to wait hours for a triaging report.
- Thou shalt try hard: If for some reason the analysis fails (could be an OpenRouter issue for instance), the model gets a (single) second chance.
The tournament will be split in two distinct events:
-
A triaging event: 2 clean, 1 PUA and 6 malicious samples have been hand-picked, from PE malware to malicious office documents, including .NET and Golang. LLMs are tasked with creating a simple triaging report and providing evidence for their decision. The models will be evaluated on:
- Final verdict (7 points) : here we will not only note the result, but also evaluate the relevance of the evidence
- IOCs extracted (5 points) : here we want to see how deep the LLM went
- Time (4 points) : 1 point per minute under 5 minutes
- Cost (4 points) : 0€ gets you 4 points, 0.25€ 3 points .. up to 1€ and more: 0 point
- Tokens limit : 500k
-
A static unpacking event: here the LLMs will be tasked with statically unpacking 5 hand-picked malware samples with interesting packing chains using only Malcat and its transforms. The goal here is to assess how well a model can understand code, locate anomalies and call complex tools. The scoring will be as follows:
- Payloads extracted (12 points) : how many payloads were successfully extracted. We may give partial points when the payload has been found and/or the decryption parameters have been reverse engineered, even in the absence of the final payload.
- Time (4 points) : 1 point per minute under 5 minutes
- Cost (4 points) : 0€ gets you 4 points, 0.50€ 3 points .. up to 2€ and more: 0 point
- Tokens limit : 800k
I'm well aware that the scoring is arbitrary. It corresponds to what I expect from a model personally, and your expectations may be completely different. The score will be broken down into its constituents, so feel free to use your own weights!
The weapon ⚔️
This is not a benchmark of LLMs working from raw files, and it is not a neutral comparison of malware-analysis platforms. For every sample, each model has access to (and only to) Malcat through its MCP server and uses the same set of analysis features. For reproducibility, here is what the MCP server exposed to every model:
- File-format parsing:
- Models can parse 60+ file formats and access their structures, symbols and metadata
- File extraction:
- Models may carve and extract sub-files for most archives, programs and installer types
- Code analysis:
- Models get access to the reconstructed CFG and can disassemble and decompile functions and follow (in)direct references, callers/callees, etc.
- Data analysis:
- Models get access to the list of extracted strings, sorted by score (so they get the most important strings first), and can query entropy values in the file
- Pattern matching:
- Malcat scans for more than 400k constants, 2.5k YARA signatures and 200+ anomalies. Models have access to the scan results and, more importantly, to the pattern hit locations
- Kesakode lookup:
- Every analysis starts with an online Kesakode lookup. This tags each function as either clean, library, malware or unknown, helping the models a lot in practice
- Malcat transforms:
- Models can apply a list of data transforms (CyberChef-style) to any part of the file, choosing between more than 80 available algorithms
- Built-in unpackers:
- Malcat gives access to a couple of specialised unpackers, such as a Donut unpacker or UPX unpacker. This should come in handy for the second challenge.
The models cannot perform shell commands, run Python scripts or do web searches. In practice, this means that when a model succeeds, the result usually comes from a combination of Malcat exposing the right artifacts and the model choosing the right things to inspect. When a model fails, it may be because the reasoning failed, because the model used the tools poorly, or because Malcat did not expose the right information, or not clearly enough.
The participants 🦾
Here is the list of models that will be tested. For more info, you can refer to their descriptions on the OpenRouter models page:
| Manufacturer | model | release date | openrouter id |
|---|---|---|---|
| Amazon | Nova 2 Lite | Dec. 2025 | amazon/nova-2-lite-v1 |
| Anthropic | Opus 4.7 | Apr. 2026 | anthropic/claude-opus-4.7 |
| DeepSeek | DeepSeek v4 Pro | Apr. 2026 | deepseek/deepseek-v4-pro |
| Gemini 3.1 Pro Preview | Feb. 2026 | google/gemini-3.1-pro-preview |
|
| MiniMax | MiniMax M1 | June 2025 | minimax/minimax-m1 |
| OpenAI | GPT 5.51 | Apr. 2026 | openai/gpt-5.5 |
| X AI | Grok 4.3 | May 2026 | x-ai/grok-4.3 |
| Xiaomi | Mimo 2.5 Pro | Apr. 2026 | xiaomi/mimo-v2.5-pro |
There were other models I wanted to test, but either their context window was too small, they blocked the output (I'm looking at you nova-premier-v1) or their availability was too unstable for the test (like the excellent deepseek-v4-flash, victim of its success I guess).
Triage contest
Let us start with the first challenge: the writing of triaging reports for 9 hand-picked binaries. I can see this feature being pretty useful for SOC teams: in a couple of minutes you can get a second opinion which will be valuable for everyone. The prompt looks something like this (I have omitted the list of file-type-specific directions for the sake of clarity):
You are tasked to analyse a file using Malcat MCP. Your main goal is to decide if the file is malicious or clean. The result of your analysis shall take the form of a textual report.
Analysis workflow
-----------------
Analysing a file is usually done as follows:
* First, gather some high-level info about the sample, such as any framework or compiler used
* List virtual and carved files
* Look at the matching YARA rules, anomalies, constants
* Look at the most interesting strings.
* Inspect a couple of interesting functions
* To complete your analysis, you may follow back the references of the most pertinent strings / constants and analyse the code referencing them
Programs may be like Russian dolls and include several sub-files/resources. If it makes sense, you may analyse said sub-files and apply the same workflow.
Some file types require a specific approach: <omitted>
Report generation
-----------------
Using this information, write a small report assessing if the file is malicious or not and its main behavior. It shall be formatted as follows:
1. Generic info about the file (type, metadata, frameworks used, interesting notes)
2. Inferred behavior: explain the main content/goal/behavior of the file
3. Sub-files: list the sub-files that were pertinent for the analysis and some info about them.
4. IOCs: any extracted IOCs
5. Key detections: list all the elements that you think point towards malware
6. Counter arguments: list the arguments that tell you that the file may be clean, or in the case of malware, list the possible shortcomings of your key detections
7. Final verdict, with a confidence score.
The report shall have the following headings: Summary, Key detections/IOCs, Evidence, Verdict.
This will test the capacity of the LLM to browse through the file and its sub-files (if any), correlate different elements and also test its knowledge about malware. And as you will see below, the results are pretty impressive, even if we consider the relatively low token limit that has been set for this challenge: 500k tokens.
I'll try to include links to some of the reports (at least the best ones) if you want to judge by yourself
Binary #1: Zig downloader
- Sample:
- 9da5191c78e49b46e479cdfe20004a9d76ccc4a545deeb83e3c07f83db9cf736 (VT, Bazaar)
- Type:
- Malicious x64 PE binary
- Description:
- A signed Zig downloader (see basic report)
For the first test, we will start with an easy catch. This is a very straightforward Zig downloader with a couple of anti-VM tricks, similar to what we already analysed in a previous blog post. Since the models have access to Kesakode online lookups, there are very few non-clean strings and functions left to analyse. The only pitfall is the certificate. It is of course invalid, but Malcat does not verify certificates (it's on the TODO list, yes), so models will have to disregard this artifact.
Extra points in the IOC section for identifying Zig and extracting the URL and file names. In the verdict department, points will be given for the verdict, behavior, and for each identified anti-sandbox technique.

So let us see what our participants are saying:
| model | usage (tokens/tools) | time | total cost | IOC extracted | verdict | total |
|---|---|---|---|---|---|---|
| mimo-v2.5-pro | 455k (35 calls) | 1.9/4 (158s) | 2.9/4 (0.28€) | 5/5 | 6/7 (85% and missing some anti-*) | 15.8/20 |
| gpt-5.5 | 347k (39 calls) | 2.4/4 (118s) | 0.2/4 (0.94€) | 5/5 | 7/7 (very good) | 14.7/20 |
| qwen3.6-plus | 691k (26 calls) | 2.3/4 (130s) | 3.1/4 (0.23€) | 5/5 | 4/7 (no anti-*, lack of evidence) | 14.3/20 |
| deepseek-v4-pro | 223k (21 calls) | 1/4 (222s) | 2.4/4 (0.41€) | 5/5 | 5/7 (no anti-*) | 13.4/20 |
| nova-2-lite-v1 | 506k (14 calls) | 3.7/4 (20s) | 3.4/4 (0.15€) | 2/5 | 4/7 (no anti-*, 85%) | 13.1/20 |
| grok-4.3 | 52k (8 calls) | 3.7/4 (21s) | 3.8/4 (0.04€) | 2/5 | 3/7 (verdict ok, but that's it) | 12.5/20 |
| claude-opus-4.7 | 667k (20 calls) | 2.4/4 (121s) | 0/4 (3.51€) | 5/5 | 5/7 (no anti-*) | 12.4/20 |
| gemini-3.1-pro-preview | 714k (17 calls) | 3.2/4 (63s) | 0.5/4 (0.87€) | 4/5 (no Zig) | 4/7 (no anti-*, behavior) | 11.7/20 |
| minimax-m1 | 432k (18 calls) | 3/4 (77s) | 3.2/4 (0.19€) | 5/5 | 2/7 (weak clean, but good arguments) | 11.2/20 |
Thank you Claude for emptying my wallet, @#! Besides this, most models did well in this first test, as expected.
Binary #2: Busybox
- Sample:
- a344eab689251264b208fabbbf23c7d12e652e9b372957af916446142398c382 (VT)
- Type:
- Clean Armv7 ELF binary
- Description:
- Armv7 busybox shell (see basic report)
I can imagine that BusyBox could be problematic for some models. It features a bit of everything: disk access, network access, an HTTP server and even a single high-entropy buffer. Since it's a clean file, the points will be given as follows:
- IOC: points for identifying BusyBox, its version and port
- Verdict: points for each evidence pointing towards clean, and also for each described behavior
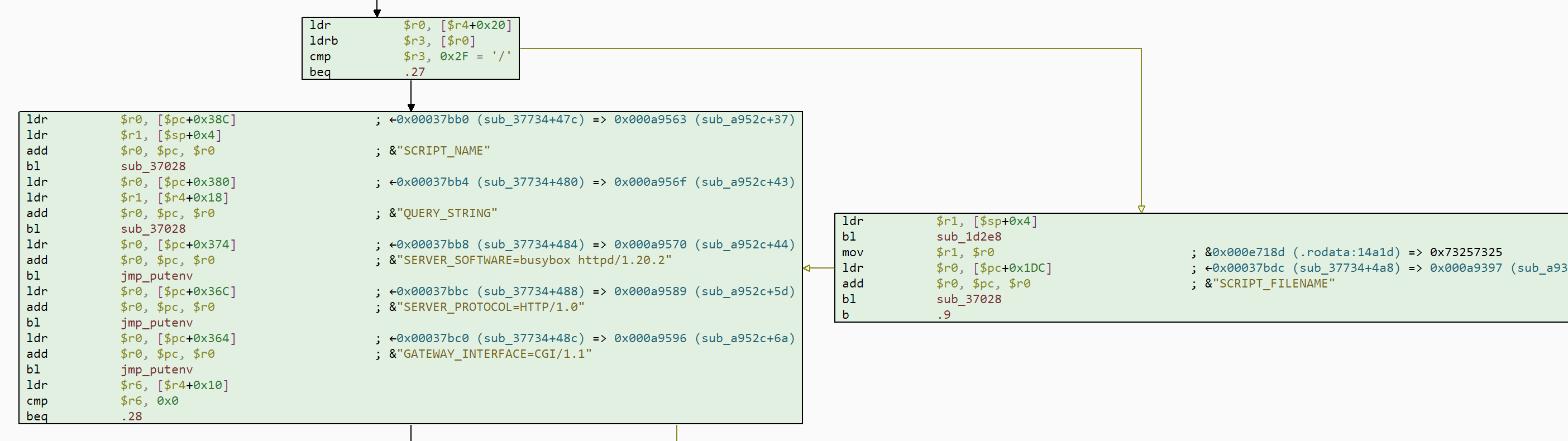
So let us see which model falls for it:
| model | usage (tokens/tools) | time | total cost | IOC extracted | verdict | total |
|---|---|---|---|---|---|---|
| mimo-v2.5-pro | 582k (54 calls) | 2.5/4 (114s) | 3.1/4 (0.21€) | 5/5 | 6.5/7 | 17.1/20 |
| qwen3.6-plus | 576k (18 calls) | 2.4/4 (121s) | 3.2/4 (0.19€) | 5/5 | 6/7 | 16.6/20 |
| minimax-m1 | 416k (21 calls) | 3.2/4 (57s) | 3.3/4 (0.19€) | 5/5 | 5/7 (missing behavior) | 16.5/20 |
| gpt-5.5 | 433k (60 calls) | 2.6/4 (104s) | 1.4/4 (0.65€) | 5/5 | 7/7 (good reasoning and evidence) | 16/20 |
| claude-opus-4.7 | 174k (16 calls) | 3/4 (71s) | 0.2/4 (0.96€) | 5/5 | 6/7 | 14.2/20 |
| deepseek-v4-pro | 556k (39 calls) | 0/4 (310s) | 1.4/4 (0.64€) | 5/5 | 6/7 | 12.4/20 |
| gemini-3.1-pro-preview | 538k (35 calls) | 2.3/4 (124s) | 2.4/4 (0.4€) | 5/5 | 4/7 (light evidence) | 13.7/20 |
| grok-4.3 | 27k (4 calls) | 3.7/4 (21s) | 3.9/4 (0.03€) | 0/5 | 3/7 (low confidence, missing behavior) | 10.6/20 |
| nova-2-lite-v1 | 112k (9 calls) | 3.8/4 (17s) | 3.9/4 (0.04€) | 0/5 | 0/7 (likely malicious) | 7.6/20 |
I'm not sure if I'm being very fair, since I guess some models thought they did not need to provide behavior since the verdict was clean. Anyway, rules are rules.
Note that the DeepSeek time may have been influenced by DeepSeek's current all-time high demand
Binary #3: Excel macros
- Sample:
- 00189ae30ede41db97df3adb41e962c6d08534ca421cf30147b23d1cd46f2228 (VT, Malshare)
- Type:
- Malicious Excel document
- Description:
- A very straightforward Excel downloader. Download is done via Excel macros, URLs are slightly obfuscated (see basic report)
This sample is a very simple downloader that anyone would detect as malicious in 2 seconds (well, if you're the right tool at least). The only thing the model has to do is open the Workbook stream and call Malcat's decompile tool to get the Excel formula. The URLs are slightly obfuscated (see below), and the model will get all 5 IOC points if it can deobfuscate them.
The download code is also obfuscated. Extra points in the verdict will be awarded if the API names were retrieved.

| model | usage (tokens/tool calls) | time | total cost | IOC extracted | verdict | total |
|---|---|---|---|---|---|---|
| mimo-v2.5-pro | 441k tokens (81 calls) | 1.2/4 (211s) | 3.4/4 (0.14€) | 5/5 | 7/7 | 16.6/20 |
| gemini-3.1-pro-preview | 546k tokens (52 calls) | 2.4/4 (122s) | 2.3/4 (0.44€) | 5/5 | 7/7 (even if very concise) | 16.6/20 |
| claude-opus-4.7 | 139k tokens (22 calls) | 2.8/4 (91s) | 0.8/4 (0.79€) | 5/5 | 7/7 (even if it did not call decompile() !) | 15.6/20 |
| qwen3.6-plus | 542k tokens (49 calls) | 2/4 (153s) | 3.3/4 (0.19€) | 3/5 (partial URLs) | 7/7 | 15.2/20 |
| gpt-5.5 | 551k tokens (49 calls) | 2.4/4 (123s) | 0.3/4 (0.92€) | 5/5 | 7/7 (also got the APIs) | 14.7/20 |
| minimax-m1 | 522k tokens (34 calls) | 2.4/4 (122s) | 3.1/4 (0.24€) | 2/5 (forgot the URLs!) | 7/7 (but got the rest right) | 14.4/20 |
| deepseek-v4-pro | 560k tokens (85 calls) | 0/4 (622s) | 0.7/4 (0.81€) | 5/5 | 7/7 | 12.7/20 |
| grok-4.3 | 38k tokens (6 calls) | 3.7/4 (20s) | 3.8/4 (0.04€) | 1/5 (got a .html suffix) | 2/7 (weak 70% malware verdict with little evidence) | 10.6/20 |
| nova-2-lite-v1 | 74k tokens (7 calls) | 3.8/4 (16s) | 3.9/4 (0.02€) | 0/5 | 0.5/7 (clean, but 0.5 points for pointing the Russian metadata) | 8.2/20 |
No surprise there, it's a walk in the park for most models. I was a bit surprised that Claude called the wrong tool, but it did get everything right in the end, so I'll close my eyes.
Note that the DeepSeek time may have been influenced by DeepSeek's current all-time high demand
Binary #4: SFX CAB to AutoIT
- Sample:
- 6b08010bf6a5148ea64abdea3edfac0ed11a27137def1f8f6e6c7a996870a8e8 (VT, Bazaar)
- Type:
- Malicious Self-extracting (CAB) PE
- Description:
- A self-extracting CAB file that drops several files.
Crap.aacis the (obfuscated) launched batch script that will reassemble the files into a valid AutoIT exe and run it (see basic report)
With this sample we increase the difficulty a lot. First the model has to read the POSTRUNPROGRAM resource from the self-extracting CAB and ignore the rest of the PE stub. This should give an entry point to the CAB archive. It will then have to open the CAB archive, locate the batch script, deobfuscate it and get the right command to reassemble the AutoIT file. To be honest, I don't expect any model to achieve this in only 500k tokens. But this will put their tool-calling capabilities to the test.
I'll give the full IOC points if all technology and file names in the chain are identified (CAB SFX, AutoIT and the batch script). For the verdict, of course points for the decision, but also for the file-reassembling algorithm and (but I don't believe it) for analysing the final reassembled AutoIT script.
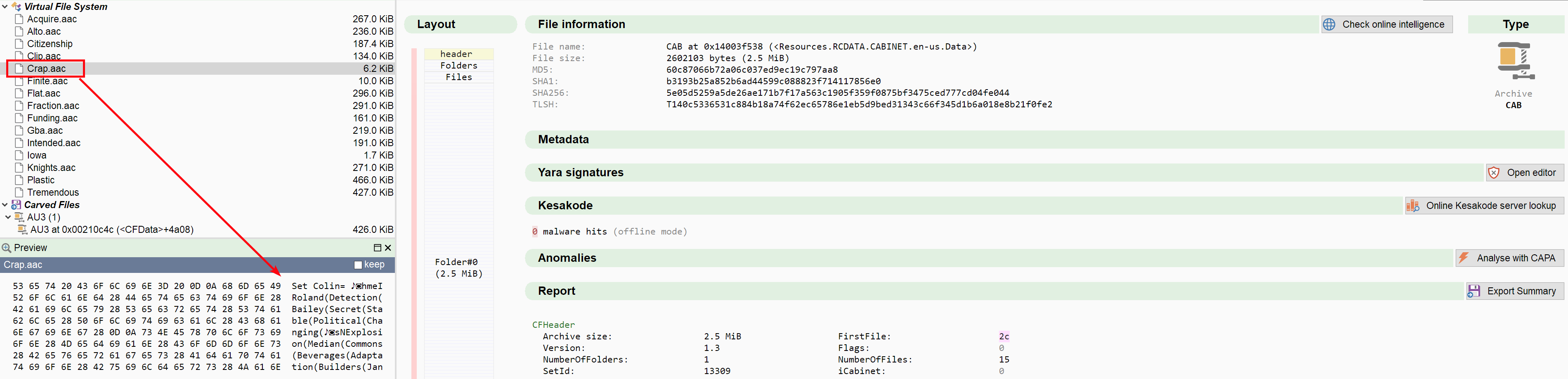
| model | usage (tokens/tools) | time | total cost | IOC extracted | verdict | total |
|---|---|---|---|---|---|---|
| gpt-5.5 | 349k (65 calls) | 2/4 (153s) | 0.2/4 (0.94€) | 5/5 | 6/7 (got the reassembling, nice report) | 13.2/20 |
| mimo-v2.5-pro | 560k (59 calls) | 0.8/4 (239s) | 3.1/4 (0.23€) | 5/5 | 4/7 (got a rough idea) | 12.9/20 |
| qwen3.6-plus | 540k (42 calls) | 1.3/4 (200s) | 3.2/4 (0.19€) | 3/5 (missed AutoIT) | 4/7 (got a rough idea) | 11.6/20 |
| minimax-m1 | 531k (34 calls) | 2.2/4 (137s) | 3/4 (0.24€) | 3/5 (missed AutoIT) | 3/7 (missed the reassembling) | 11.2/20 |
| grok-4.3 | 41k (6 calls) | 3.6/4 (28s) | 3.8/4 (0.04€) | 1/5 (just the CAB) | 1/7 (admitted it can't decide) | 9.4/20 |
| nova-2-lite-v1 | 169k (12 calls) | 3.8/4 (19s) | 3.8/4 (0.05€) | 1/5 (got the SFX) | 1/7 (admitted it can't decide) | 9.5/20 |
| gemini-3.1-pro-preview | 533k (48 calls) | 2.2/4 (132s) | 1.7/4 (0.57€) | 2/5 (missed POSTRUNPROGRAM and batch) | 3/7 (missed the reassembling part) | 9/20 |
| deepseek-v4-pro | 561k (46 calls) | 0/4 (807s) | 0.8/4 (0.81€) | 5/5 | 0/7 | 5.8/20 |
| claude-opus-4.7 | 352k (26 calls) | 0/4 (383s) | 0/4 (1.82€) | 5/5 | 0/7 | 5/20 |
Definitely a harder case to crack for our LLMs. No model could (or even attempted to) reassemble the AutoIT file. This could be because we don't expose batch tools, but still, the models could have given some directions. But kudos to ChatGPT, which was the only one to even notice that the AAC files get concatenated and which wrote the most useful report by a large margin.
Claude and DeepSeek could not complete the analysis of the batch part and got stuck on the report generation part. I could see in the log that they got most of the artifacts right, but choked miserably afterwards. I could be at fault there, because of the lack of compacting.
Binary #5: Tor node
- Sample:
- 6b866c187a0dee2fb751a8990d50dc1ed83f68e025720081e4d8e27097067dc8 (VT)
- Type:
- Clean PE program
- Description:
- the Tor program (see basic report)
The difficulty in this sample is its size: 9 MB and the bad reputation that Tor has. Plus, of course, a lot of crypto. The IOC points this round will be awarded for identifying Tor. Verdict points will be awarded for the decision, behavior and 1 point if the model says that the presence of Tor may be a sign of infection.
| model | usage (tokens/tools) | time | total cost | IOC extracted | verdict | total |
|---|---|---|---|---|---|---|
| mimo-v2.5-pro | 589k (51 calls) | 2.4/4 (118s) | 3/4 (0.24€) | 5/5 | 7/7 | 17.4/20 |
| minimax-m1 | 651k (18 calls) | 2.7/4 (99s) | 2.8/4 (0.29€) | 4/5 (missed the version) | 6/7 | 15.5/20 |
| claude-opus-4.7 | 218k (16 calls) | 3.2/4 (61s) | 0/4 (1.18€) | 5/5 | 7/7 | 15.2/20 |
| qwen3.6-plus | 578k (19 calls) | 2.7/4 (98s) | 3.2/4 (0.19€) | 4/5 (missed the version) | 5/7 (no behavior) | 14.9/20 |
| grok-4.3 | 25k (4 calls) | 3.8/4 (16s) | 3.9/4 (0.02€) | 4/5 (missed the version) | 3/7 (no behavior, bad report) | 14.7/20 |
| gpt-5.5 | 457k (42 calls) | 1.5/4 (187s) | 0/4 (1.4€) | 5/5 | 7/7 | 13.5/20 |
| gemini-3.1-pro-preview | 571k (19 calls) | 2.2/4 (131s) | 1.2/4 (0.7€) | 4/5 (missed the version) | 6/7 | 13.5/20 |
| deepseek-v4-pro | 598k (27 calls) | 0/4 (311s) | 1.4/4 (0.65€) | 5/5 | 6/7 | 12.4/20 |
| nova-2-lite-v1 | 129k (9 calls) | 3.8/4 (15s) | 3.8/4 (0.04€) | 2/5 (TOR) | 0/7 (malicious) | 11.5/20 |
An easy decision for most models; there was little difference between all the reports to be honest. Maybe this was too easy. Regarding Nova 2 Lite, I wonder how good it would be as a detector if we just took the opposite verdict every time ;)
Note that the DeepSeek time may have been influenced by DeepSeek's current all-time high demand
Binary #6: Rust dropper
- Sample:
- 3c47eccd8fc8d9a9ce087c5ff5f9dce08d5dd15123b84a44301ca98b6a4f797d (VT)
- Type:
- Malicious Rust PE program
- Description:
- A Rust dropper that contains a huge base64 string which is further XORed with 0x83, and decrypts to an MZ file (see basic report)
This sample shall also be relatively easy to triage, but it has some additional depth because of its two stages. IOC points will be given if the model can identify the persistence mechanisms (registry key and drop path), and detect that it is Rust (well Malcat does, so rather easy). Verdict points will reward the relevance of the arguments and reaching the end of the drop chain. Note that there is a difficulty: because of how Rust addresses strings and their lack of terminators, Malcat has to rely on a heuristic to recover usable strings. In this case, the size of the base64 string is too short, which should prove difficult for the models!

| model | usage (tokens/tools) | time | total cost | IOC extracted | verdict | total |
|---|---|---|---|---|---|---|
| mimo-v2.5-pro | 441k (41 calls) | 2.3/4 (130s) | 3.2/4 (0.21€) | 5/5 | 5/7 (found payload loc.) | 15.4/20 |
| qwen3.6-plus | 587k (27 calls) | 2/4 (149s) | 3.2/4 (0.2€) | 5/5 | 4/7 (weak decision, no algorithm) | 14.2/20 |
| minimax-m1 | 549k (18 calls) | 3/4 (78s) | 3/4 (0.24€) | 4/5 | 4/7 (no algorithm, short, good arguments) | 14/20 |
| grok-4.3 | 38k (7 calls) | 3.8/4 (18s) | 3.9/4 (0.03€) | 2/5 | 3/7 (weak decision, no algo, short) | 12.6/20 |
| gemini-3.1-pro-preview | 602k (49 calls) | 2.2/4 (135s) | 1.2/4 (0.69€) | 5/5 | 4/7 (no algorithm) | 12.4/20 |
| claude-opus-4.7 | 416k (25 calls) | 2.7/4 (100s) | 0/4 (2.21€) | 4/5 | 5/7 (found decryption algorithm) | 11.7/20 |
| gpt-5.5 | 811k (45 calls) | 1.2/4 (211s) | 0/4 (2.98€) | 4/5 | 5/7 (found decryption algorithm) | 10.2/20 |
| deepseek-v4-pro | 709k (27 calls) | 0/4 (334s) | 0/4 (1.23€) | 5/5 | 5/7 (found decryption algorithm) | 10/20 |
| nova-2-lite-v1 | 253k (9 calls) | 3.4/4 (43s) | 3.7/4 (0.08€) | 0/5 | 2/7 (right verdict, but that's just luck) | 9.1/20 |
Note that the DeepSeek time may have been influenced by DeepSeek's current all-time high demand
No model got to the end of the infection chain here, which is a bit disappointing. Nonetheless, most got the decryption algorithm or the payload location right, which is already pretty useful.
Binary #7: Code dropper
- Sample:
- 0dc710737c12ea1c1215fbd39e00347649fff1fb0e512287c86873f66a9f0a35 (VT, Bazaar)
- Type:
- Malicious PE program
- Description:
- A dropper from the .text section with numerous, but somewhat subtle, anomalies (see basic report)
This sample could be slightly tricky because of the way it has been generated. I guess a (signed) clean application has been used as a source, and a malicious dropper has been patched in. Additionally, the code section is obfuscated, but in a slightly subtle way. Even worse, the encrypted payload has medium entropy. As a consequence, what is suspicious here is not a big blinking artifact but rather the absence of some artifacts:
- there is a 600 KB cavity in the text section, between the dropper code and the encrypted payload
- there is no referenced string in the data section
- there is a 4 KB gap at the end of the resource section (version info has been patched I guess)
- imports don't really make sense
- weird resource language
Let's see if our models can look behind the obvious.

IOC points will be awarded when spotting what is wrong. Verdict points will be awarded for the right call, locating the payload, its decryption algorithm and the relevance of the arguments. I'll look in particular for arguments citing the obfuscation.
| model | usage (tokens/tools) | time | total cost | IOC extracted | verdict | total |
|---|---|---|---|---|---|---|
| gpt-5.5 | 180k (33 calls) | 2.9/4 (81s) | 2.1/4 (0.47€) | 4/5 | 6/7 (no dec. alg.) | 15/20 |
| mimo-v2.5-pro | 565k (43 calls) | 1.8/4 (165s) | 3.1/4 (0.23€) | 5/5 | 5/7 (-1 because it said payload in data, no dec. alg.) | 14.9/20 |
| qwen3.6-plus | 608k (35 calls) | 1.4/4 (192s) | 3.2/4 (0.21€) | 5/5 | 5/7 | 14.6/20 |
| gemini-3.1-pro-preview | 153k (20 calls) | 2.8/4 (89s) | 3.3/4 (0.17€) | 4/5 | 4/7 (very barebones) | 12.1/20 |
| minimax-m1 | 561k (28 calls) | 2.3/4 (126s) | 2.7/4 (0.31€) | 4/5 | 4/7 (-1 because it said payload in data, barebones) | 12.1/20 |
| claude-opus-4.7 | 213k (16 calls) | 2.6/4 (103s) | 0/4 (1.17€) | 4/5 | 5/7 (-1 because it said payload in data, no dec. alg.) | 11.6/20 |
| deepseek-v4-pro | 557k (43 calls) | 0/4 (447s) | 1.5/4 (0.63€) | 4/5 | 6/7 (no dec. alg.) | 11.5/20 |
| grok-4.3 | 32k (6 calls) | 3.7/4 (26s) | 3.9/4 (0.02€) | 2/5 | 0/7 (clean) | 9.6/20 |
| nova-2-lite-v1 | 151k (12 calls) | 3.7/4 (25s) | 3.8/4 (0.05€) | 0/5 | 0/7 (report blocked) | 7.5/20 |
Note that the DeepSeek time may have been influenced by DeepSeek's current all-time high demand
The models were all rather good at spotting what is weird in this file. Most of them spotted the code obfuscation, the nonsensical APIs, resource and certificate. I was a bit disappointed that no model could extract the second stage, but I guess you need a few more tokens for that.
Binary #8: Patched downloader
- Sample:
- 1fd921159de8ccf3c33c7ad3d52a4186c2695b858435e8e327c4d95a8d1b048a (VT, VirusShare)
- Type:
- Malicious PE downloader
- Description:
- A likely side-loaded DLL with only a couple of patched functions (see basic report)
This one is a bit tricky, even for human analysts. If you're a bit too hasty there, you may only see what looks like a normal service DLL. Ok, the single export name looks a bit strange, but the rest looks legit. The malware writer there was smart-ish: it is a downloader, with only a couple of malicious functions buried in the otherwise clean binary. No payload to locate, nothing. Even worse, the malicious entry point is not directly the export, but a function called by one of the exports. And finally, while the download URL is in plain text, it is not referenced directly (only by its second character). By chance, Malcat's constant database gives rather hard evidence there: 5 download-related API hashes. This should be enough for most models to trigger some warnings.

IOC points will be awarded when spotting the URL, the hashes and naming the export. Verdict points will be awarded for the right call, describing the behavior (including the AES crypto) and the relevance of the arguments.
| model | usage (tokens/tools) | time | total cost | IOC extracted | verdict | total |
|---|---|---|---|---|---|---|
| mimo-v2.5-pro | 651k (33 calls) | 2.2/4 (137s) | 3/4 (0.26€) | 4/5 | 6/7 (somewhat short) | 15.1/20 |
| gemini-3.1-pro-preview | 528k (33 calls) | 2.5/4 (114s) | 2.3/4 (0.43€) | 4/5 (no url) | 6/7 (somewhat short) | 14.8/20 |
| gpt-5.5 | 497k (58 calls) | 2.3/4 (129s) | 0/4 (1.22€) | 5/5 | 7/7 | 14.3/20 |
| qwen3.6-plus | 569k (27 calls) | 1.5/4 (186s) | 3.2/4 (0.2€) | 4/5 (no export) | 5/7 (no behavior) | 13.7/20 |
| deepseek-v4-pro | 579k (40 calls) | 0/4 (437s) | 0.6/4 (0.84€) | 5/5 | 7/7 | 12.6/20 |
| claude-opus-4.7 | 621k (33 calls) | 1.9/4 (160s) | 0/4 (3.25€) | 4/5 (no url) | 6/7 | 11.9/20 |
| grok-4.3 | 25k (6 calls) | 3.8/4 (16s) | 3.9/4 (0.02€) | 1/5 | 3/7 (very barebones) | 11.7/20 |
| minimax-m1 | 358k (19 calls) | 3/4 (71s) | 3.4/4 (0.16€) | 3/5 | 1/7 (clean, some arguments) | 10.4/20 |
| nova-2-lite-v1 | 211k (11 calls) | 3.7/4 (22s) | 3.7/4 (0.07€) | 1/5 | 1/7 (inconclusive) | 9.4/20 |
Note that the DeepSeek time may have been influenced by DeepSeek's current all-time high demand
I was positively surprised by the result for this file. Only Minimax M1 made the wrong call. Of course, Malcat did help a lot there by providing numerous useful pointers, but still.
Binary #9: UPX-packed vksaver
- Sample:
- 161ee3cc94b683d301f99f64e7ec1106767b6fc3ebb0b08bef7e22e9096998f5 (VT, MalShare)
- Type:
- PUA UPX-Packed PE
- Description:
- An UPX-packed VKontakt PUA program (see basic report and the report for the UPX-unpacked binary)
For the last one, I've dug up a pretty nasty clean file: an old UPX-packed VKontakt browser "extension" which will (after an opt-in) install bundled applications. Once UPX unpacked (Malcat features an UPX unpacker), the program may dump a big XOR-encrypted buffer from .rdata to disk and run it, tamper with browser configurations and contain pictures to tell the user how to elevate privileges. Let's be honest, under time pressure I would make a mistake. Indeed I had: that's an old FP of mine from Avira that I brought home for further analysis. I did not mis-analyse this file in particular, but it was detected by one of my heuristic rules, so mistakes were still made. So let us see how our models handle this!
For this case, I will only accept a PUA (potentially unwanted application) verdict.
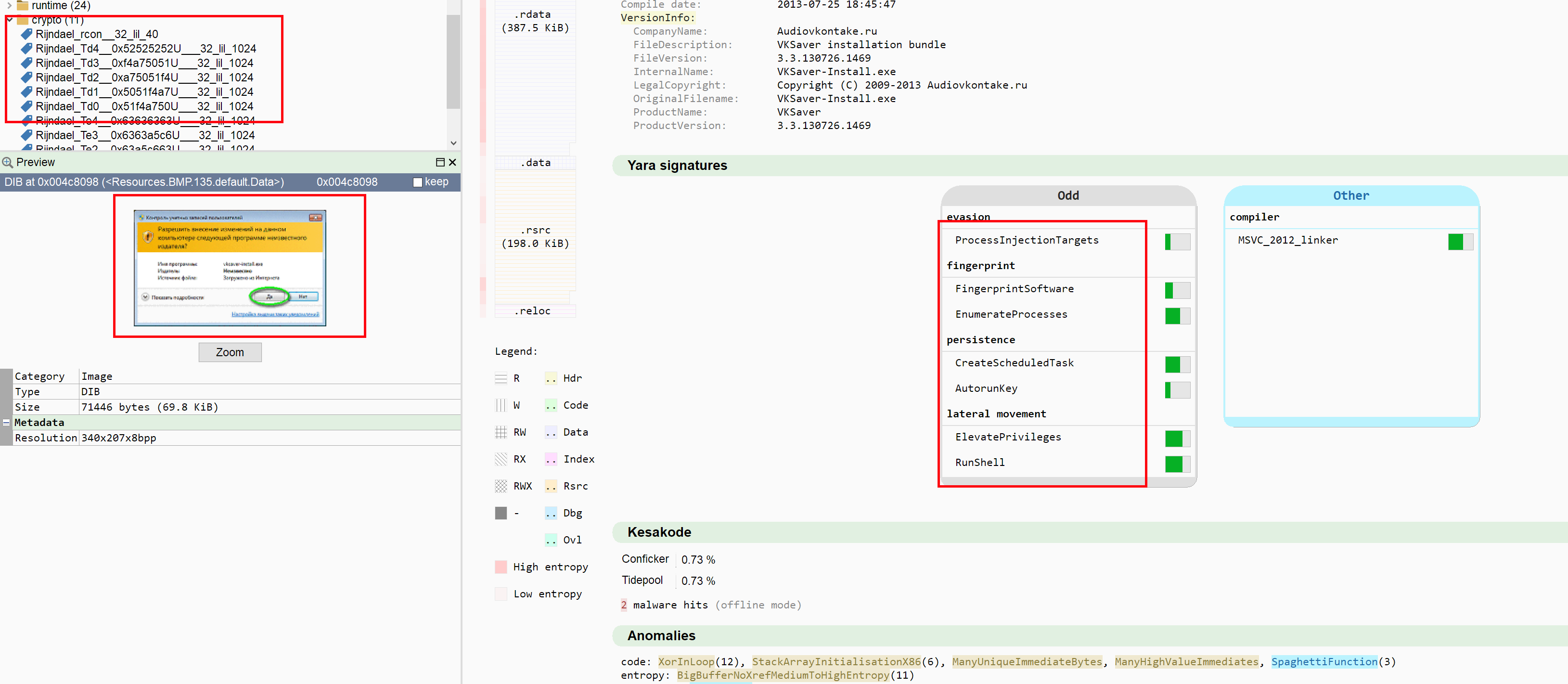
IOC points will be awarded for identifying the application, persistence and the name of the dropped files. Verdict points will be awarded for the right call, describing the behavior (including the decryption algorithm and the opt-in nature of the bundle) and the relevance of the arguments.
| model | usage (tokens/tools) | time | total cost | IOC extracted | verdict | total |
|---|---|---|---|---|---|---|
| xiaomi/mimo-v2.5-pro | 682k (44 calls) | 1.9/4 (160s) | 2.7/4 (0.33€) | 5/5 | 7/7 | 16.6/20 |
| gpt-5.5 | 670k (39 calls) | 2.4/4 (117s) | 0/4 (1.78€) | 5/5 | 7/7 | 14.4/20 |
| claude-opus-4.7 | 396k (32 calls) | 2.4/4 (119s) | 0/4 (2.13€) | 5/5 | 7/7 | 14.4/20 |
| qwen/qwen3.6-plus | 280k (15 calls) | 2.6/4 (108s) | 3.6/4 (0.1€) | 3/5 (no scheduled task) | 5/7 (no decryption, missing appinit path) | 14.2/20 |
| deepseek-v4-pro | 373k (40 calls) | 0/4 (626s) | 1.4/4 (0.64€) | 5/5 | 7/7 | 13.4/20 |
| minimax-m1 | 217k (17 calls) | 3.2/4 (62s) | 3.5/4 (0.12€) | 3/5 | 2/7 (pretty short, clean) | 11.7/20 |
| gemini-3.1-pro-preview | 522k (36 calls) | 0.9/4 (231s) | 2.4/4 (0.41€) | 5/5 | 5/7 (no decryption, missing appinit path) | 11.3/20 |
| nova-2-lite-v1 | 78k (7 calls) | 3.8/4 (16s) | 3.9/4 (0.02€) | 2/5 | 0/7 (report blocked) | 7.7/20 |
| x-ai/grok-4.3 | 39k (4 calls) | 3.7/4 (23s) | 3.8/4 (0.04€) | 0/5 | 0/7 (clean, did not open the unpacked stream) | 7.5/20 |
Pretty impressive performance by most of these models. Four models even managed to find the tokens to recover the decryption algorithm!
Note that the DeepSeek time may have been influenced by DeepSeek's current all-time high demand
Summary
After reviewing 90 (!) AI-generated reports and grading them in the most objective way I could, I have to admit I am very impressed. Most (serious) models successfully classified my 9 examples and produced useful reports, for a reasonable amount of time and money. Admittedly, Malcat gives numerous useful pointers to these models (especially Kesakode's function labeling), which makes their task definitely easier, but still, they deliver.
It would be interesting to redo this benchmark with other MCP servers and see how the models perform with less information and fewer tools
Anyway, at the end of the triage benchmark, the following scores emerged. First we look at the raw scores, i.e. how well the models perform:
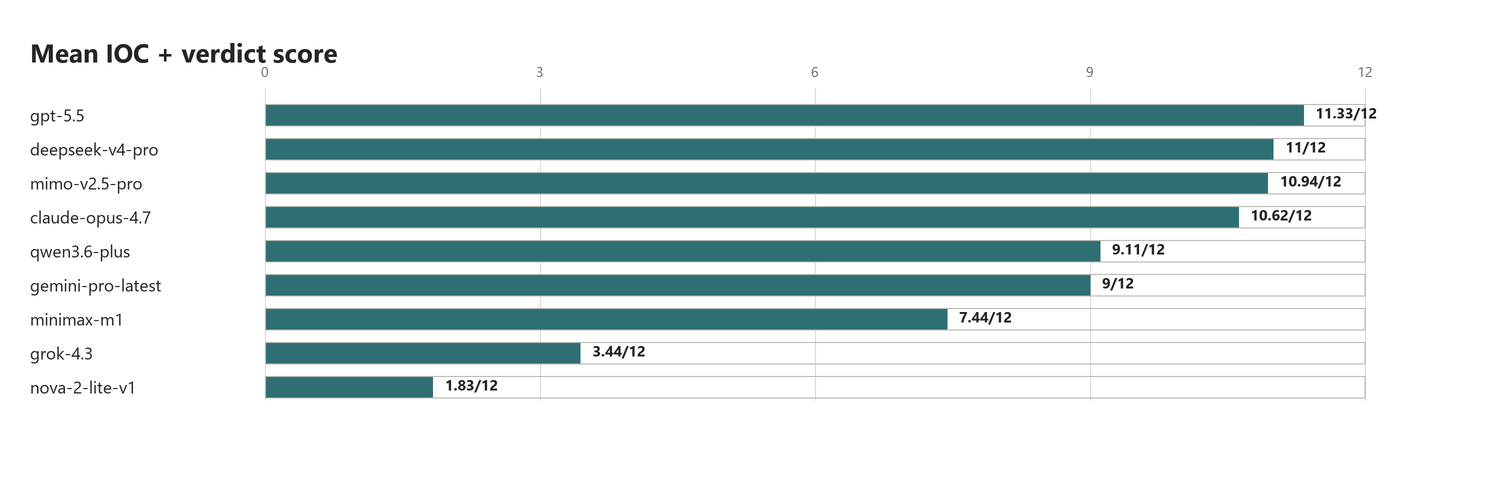
We can see here that 4 models dominate this benchmark: GPT 5.5, Opus 4.7, DeepSeek 4 Pro and a model I had not heard of before this test: Mimo 2.5 Pro. The best reports (at least to me, this is a subjective opinion) were written by GPT 5.5. GPT is a relatively verbose model, which helps for this particular benchmark. While the reports from the other 3 models were as good as GPT's, GPT systematically gave more evidence, which is very valuable for malware triage, as it gives the human analyst more pointers to verify the report and thus ultimately more confidence.
NB: Test #4 has been ignored in the mean computation for DeepSeek and Claude for all plots in this chapter since I'm not 100% sure the model was at fault there.
But what good is raw performance if you can't afford the API costs? If we take into account the other criteria I've listed at the beginning of this chapter (time and cost), we obtain the following rating:
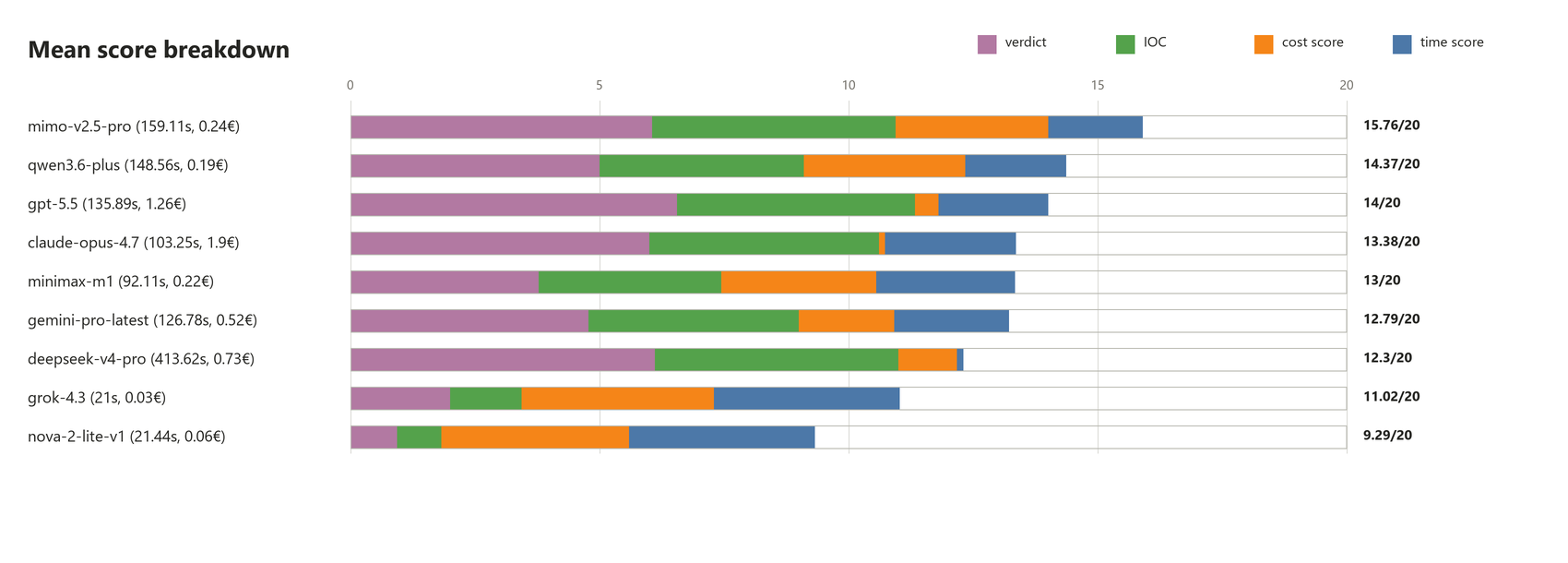
Now we get a different picture. We can see that the Chinese models offer way more performance per buck than the American ones. I was particularly impressed by Mimo 2.5 Pro, which gives very good results (almost on par with the GPT/Claude models) for only a fraction of the price. DeepSeek V4 also performs rather well, but is penalized by its pretty long inference times (which may be just a temporary issue, since its Flash model gained a lot of traction recently).
Finally, if you want to make a decision, here is a diagram on two axes that plots the raw model performance against the mean cost per analysis:
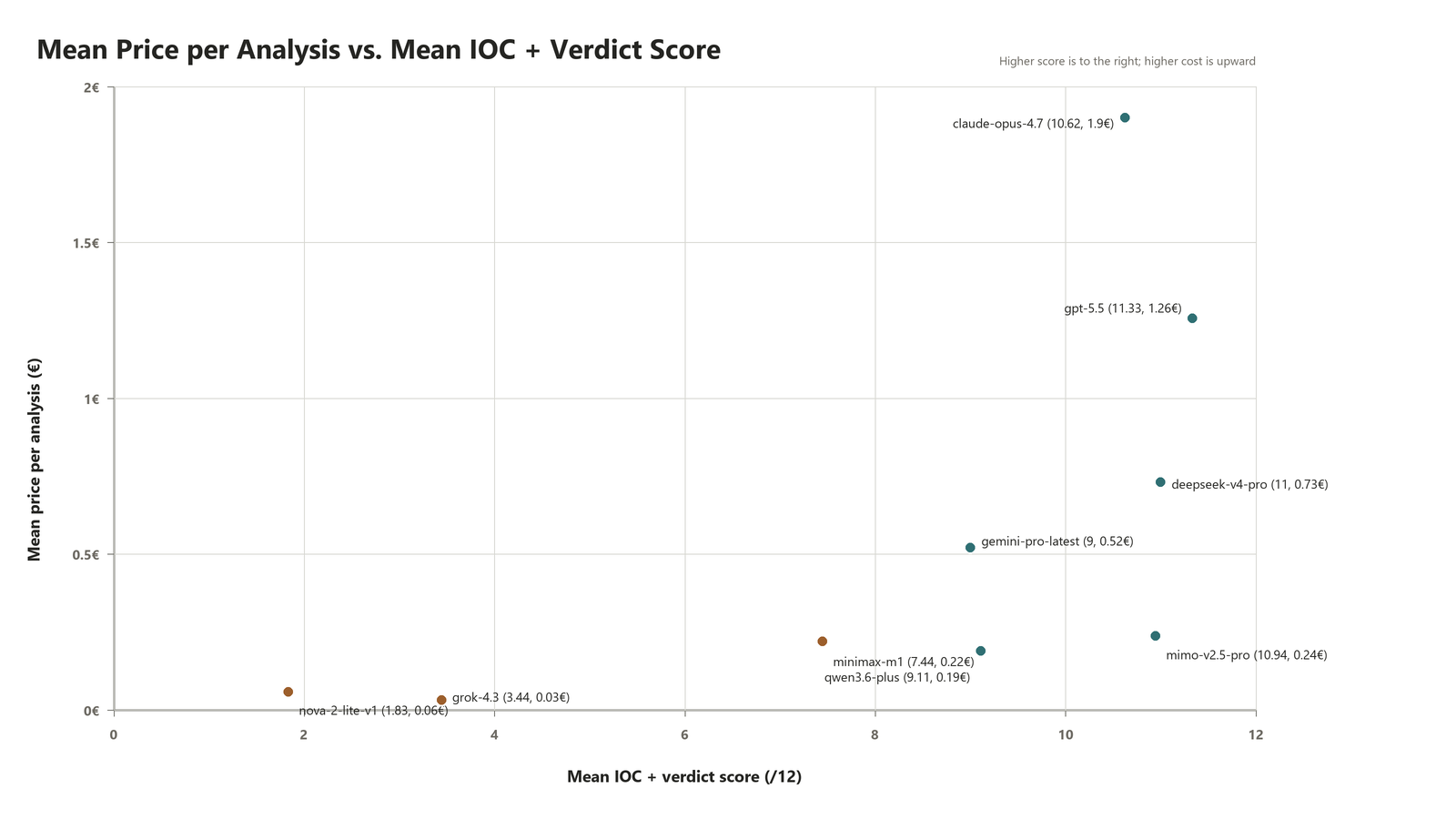
What is Anthropic doing with their pricing? For context, Claude's price per token should be the same as ChatGPT's, yet here we are.
My conclusion for my particular use case: I will include the following two models in my pipeline:
- Mimo 2.5 Pro by default because it's 100% good enough for this task and cannot be beaten in terms of bang for your buck
- GPT 5.5 for an opt-in try-hard mode, for when money is not an issue and you absolutely want the best report possible
Static unpacking contest
Now generating triage reports is a very useful use case, but it does not really allow us to precisely compare LLM models (imho) for the following reasons:
- the grading part is by definition subjective: you'll have to trust me to assess the result correctly
- summaries come very easily to LLMs, so it's not really pushing them to their limits
That's why I've come up with this second challenge: static unpacking of 5 malware samples using solely Malcat's MCP server. I know this benchmark is a bit silly: if you want to detonate and unpack samples, there are better ways. Send the samples to a sandbox (like the excellent Joe Sandbox, my personal favorite), download the memory/PE dumps and voila, you're done. Of course sandboxes have their own shortcomings (anti-xxx techniques, rather slow, expensive, may miss some artifacts), but statically unpacking samples with LLMs, while a very fun use case, is not the best use of your tokens. I usually only go this route when a sample cannot be detonated in a VM and/or no usable dump can be found in memory.
What is certain is that this challenge will push all models to their limits. Indeed, it requires the following skills:
- the model has to decide if the sample is packed
- the model has to locate the packed payload
- the model has to reverse engineer the decryption algorithm
- the model has to translate the algorithm into Malcat's transforms
Definitely harder than the first benchmark, even if Malcat will again help them there too.
NB: like for the first challenge, models won't be able to use any tools other than Malcat (i.e. no Bash nor Python), which may be a bit limiting. But there is a reason: I don't know about you, but I don't want models analysing malware unsupervised to run arbitrary code :)
The prompt that each model is given looks like the one below:
Your goal is to decide whether the sample likely embeds a packed and/or encrypted payload, and if it does, recover that payload using static analysis and Malcat transforms. If that payload is itself packed/encrypted, recurse.
Start by assessing whether the current file appears packed or encrypted:
- inspect entropy and entropy-based anomalies
- look for high-entropy regions, overlays, abnormal sections, packed-code signatures, encrypted blobs, or virtual/carved files
- compare entropy evidence against strings, constants, section names, imports, and obvious packer signatures
If there is no credible evidence of a packed or encrypted embedded payload, stop early. Produce a short report explaining why no unpacking was attempted.
If there is credible evidence of packing or encryption, try to recover the unpacking/decryption logic:
- identify the encrypted/compressed payload location, size, and format
- locate the code that reads, decodes, decrypts, decompresses, or copies the payload
- recover the algorithm and parameters when possible
- recover keys, IVs, XOR constants, rolling-key logic, compression settings, or transform chains
- use back-references from constants, strings, suspicious buffers, entropy regions, and API calls to find the relevant code
When you understand the transform, use Malcat transforms to unpack or decrypt the payload. Prefer precise transforms over broad guesses. If several stages are present, unpack them step by step and analyse the resulting file after each important stage.
After producing an unpacked file, briefly verify that it is plausible:
- check whether entropy decreased or structure became recognizable
- check file type, headers, sections, imports, scripts, strings, or other high-level indicators
- do not perform a deep behavioral analysis unless it is needed to validate that unpacking worked
If the algorithm or key cannot be recovered statically, say so and include the strongest evidence you found.
Analyse the unpacked file to see if you need to recurse. If it is not packed: abort, otherwise, unpack the new file.
I don't know about you, but I'm pretty curious to see if our models are up to the task. So let us proceed!
Unpack #1
- Sample:
- 674f19126e6dcf0ebb2bf9944841c4cd43195f73b006d51826c7c4252a7e2122 (VT, Bazaar)
- Type:
- .NET dropper
- Description:
- .NET string -> base64 -> 3des -> 404 Keylogger (see basic report)
For the first unpacking challenge, I've chosen a relatively simple sample. A .NET dropper embeds a large base64 string which gets 3DES decrypted. The only subtlety there is that the 3DES key and IV are not generated in the same control flow path as the one where the decryption takes place, since the decryption happens in an asynchronous task. So the model will have to correlate both, which is honestly rather easy.
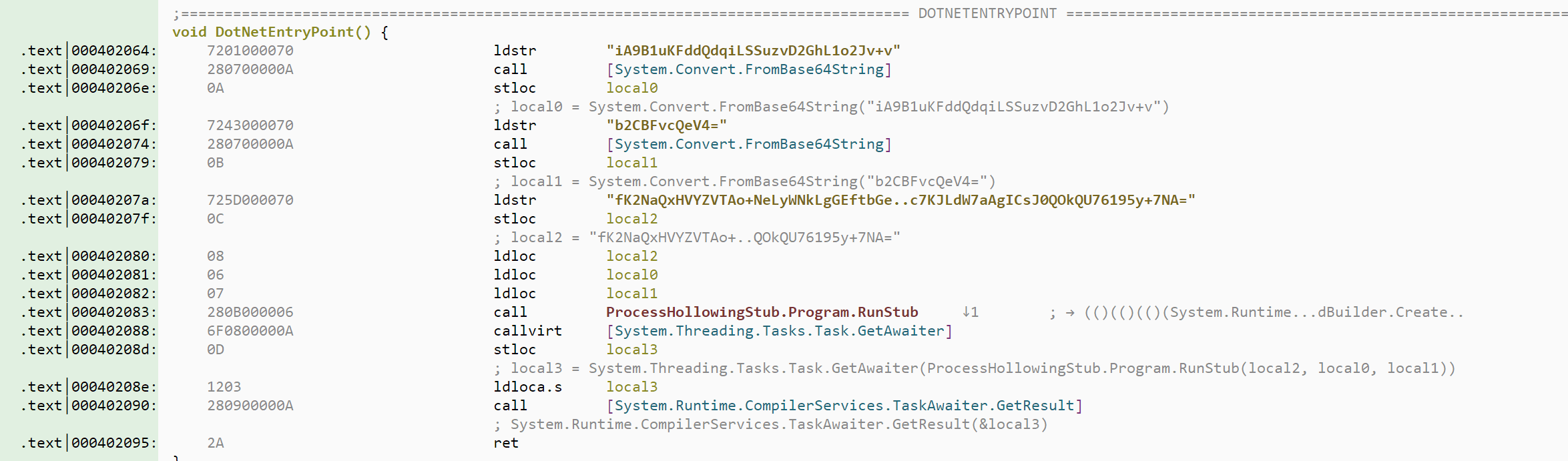
I expect all models to at least locate the payload, thanks to Malcat's HugeStringBase64 anomaly!
| model | usage (tokens/tools) | time | total cost | Unpacked chain | total |
|---|---|---|---|---|---|
| gemini-3.1-pro-preview | 243k (24 calls) | 2.8/4 (93s) | 3.6/4 (0.21€) | 12/12 | 18.3/20 |
| deepseek-v4-pro | 282k (31 calls) | 1.4/4 (192s) | 3.4/4 (0.31€) | 12/12 | 16.8/20 |
| gpt-5.5 | 516k (51 calls) | 2.6/4 (102s) | 2.1/4 (0.96€) | 12/12 | 16.7/20 |
| claude-opus-4.7 | 287k (24 calls) | 2.8/4 (94s) | 1/4 (1.52€) | 12/12 | 15.7/20 |
| qwen3.6-plus | 864k (50 calls) | 0/4 (378s) | 3.4/4 (0.31€) | 12/12 | 15.4/20 |
| mimo-v2.5-pro | 396k (37 calls) | 0/4 (411s) | 3.4/4 (0.29€) | 11/12 (-1 because missing report) | 14.4/20 |
| minimax-m1 | 824k (42 calls) | 0.2/4 (283s) | 3/4 (0.48€) | 8/12 (got payload, keys and algo, failed to apply transform) | 11.3/20 |
| grok-4.3 | 31k (4 calls) | 3.7/4 (20s) | 4/4 (0.02€) | 0/12 | 7.7/20 |
| nova-2-lite-v1 | 268k (18 calls) | 3.7/4 (22s) | 3.8/4 (0.08€) | 0/12 (says clean TT) | 7.5/20 |
This first challenge is a walk in the park for most models. .NET is rather simple to analyse, and it shows. Special distinction for Gemini 3.1 Pro, which managed to unpack the sample using only 243k tokens and 93s!
Unpack #2
- Sample:
- a64e4bbea5983eefb772b8b467504f6242c913e98a8c7fa9a6fd6e4b9a3631de (VT, Bazaar)
- Type:
- Golang PE
- Description:
- A simple single-stage rdata dropper, encryption: add 0xc4 + reverse -> Remus (see basic report)
The second unpacking challenge is also rather simple: a Golang malware that drops an encrypted Remus instance from its rdata section. I say easy mostly because:
- Malcat points directly to the payload with its
BigBufferNoXrefMediumToHighEntropyanomaly - Not a lot of unknown code to analyse thanks to Kesakode
- The decryption algorithm is really simple
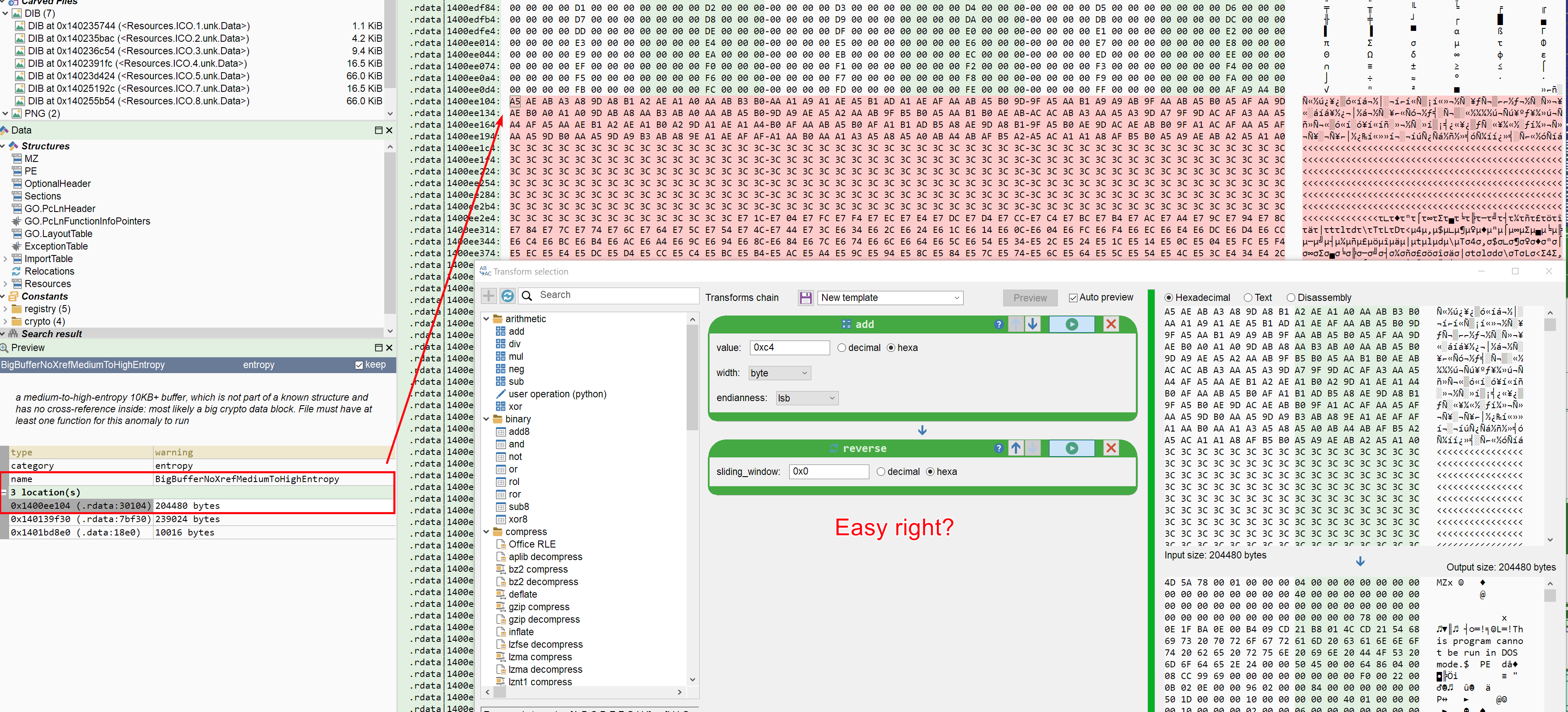
Anyway, let us have a look at the results. Note that like for all the following challenges, I may give points for partial results too (e.g. payload located or decryption algorithm reversed).
| model | usage (tokens/tools) | time | total cost | Unpacked chain | total |
|---|---|---|---|---|---|
| claude-opus-4.7 | 546k (28 calls) | 2.2/4 (133s) | 0/4 (2.88€) | 12/12 | 14.2/20 |
| gpt-5.5 | 864k (64 calls) | 1.8/4 (166s) | 1.6/4 (1.21€) | 10/12 (payload offset off by 32 bytes) | 13.4/20 |
| mimo-v2.5-pro | 963k (74 calls) | 0/4 (937s) | 3.1/4 (0.45€) | 8/12 (got payload + alg., no artifact) | 11.1/20 |
| qwen3.6-plus | 888k (48 calls) | 0.5/4 (266s) | 3.4/4 (0.31€) | 4/12 (got the payload, thought it was chacha20) | 7.8/20 |
| grok-4.3 | 23k (3 calls) | 3.8/4 (15s) | 4/4 (0.02€) | 0/12 | 7.8/20 |
| nova-2-lite-v1 | 161k (12 calls) | 3.8/4 (16s) | 3.9/4 (0.05€) | 0/12 (clean, not packed) | 7.7/20 |
| gemini-3.1-pro-preview | 56k (17 calls) | 3.7/4 (20s) | 3.8/4 (0.09€) | 0/12 (no report, no artifact) | 7.6/20 |
| minimax-m1 | 866k (37 calls) | 0.5/4 (262s) | 3/4 (0.49€) | 0/12 (clean, not packed) | 3.5/20 |
| deepseek-v4-pro | 325k (40 calls) | 0/4 (394s) | 3.3/4 (0.36€) | 0/12 (clean, not packed) | 3.3/20 |
Ok, I am a bit disappointed. I thought this was an easy one. Only Opus 4.7 gave us a perfect result. GPT 5.5 also got a dump, but it got the payload offset somewhat wrong (32 bytes too early). I don't really know why (don't forget that Malcat's MCP allows models to disassemble and decompile functions too, no excuse). Since the payload gets reversed at the end, it means that we miss the start of the MZ header, too bad!
Finally, Mimo 2.5 Pro got the decryption algorithm reversed perfectly, but could not build the right transform chain (got confused between VAs, EAs and offsets somehow). For all the other models: shame!
Unpack #3
- Sample:
- fa755134d9c9796b2f58fd61aeb0ef12121da6afaa1943f05334d332992cdff5 (VT, Bazaar)
- Type:
- Golang PE
- Description:
- Golang rdata -> AES -> Donut SC -> ValleyRAT (see basic report)
We stay in Golang territory for this third challenge, but increase the difficulty slightly. The simple XOR is now replaced by AES decryption in ECB mode, which leads to a second stage: a Donut loader. Unpacking the Donut loader gives us the final malware: ValleyRAT. Note that Malcat natively embeds a Donut unpacker, so for this part the model just has to call the rightly named unpack_donut tool.
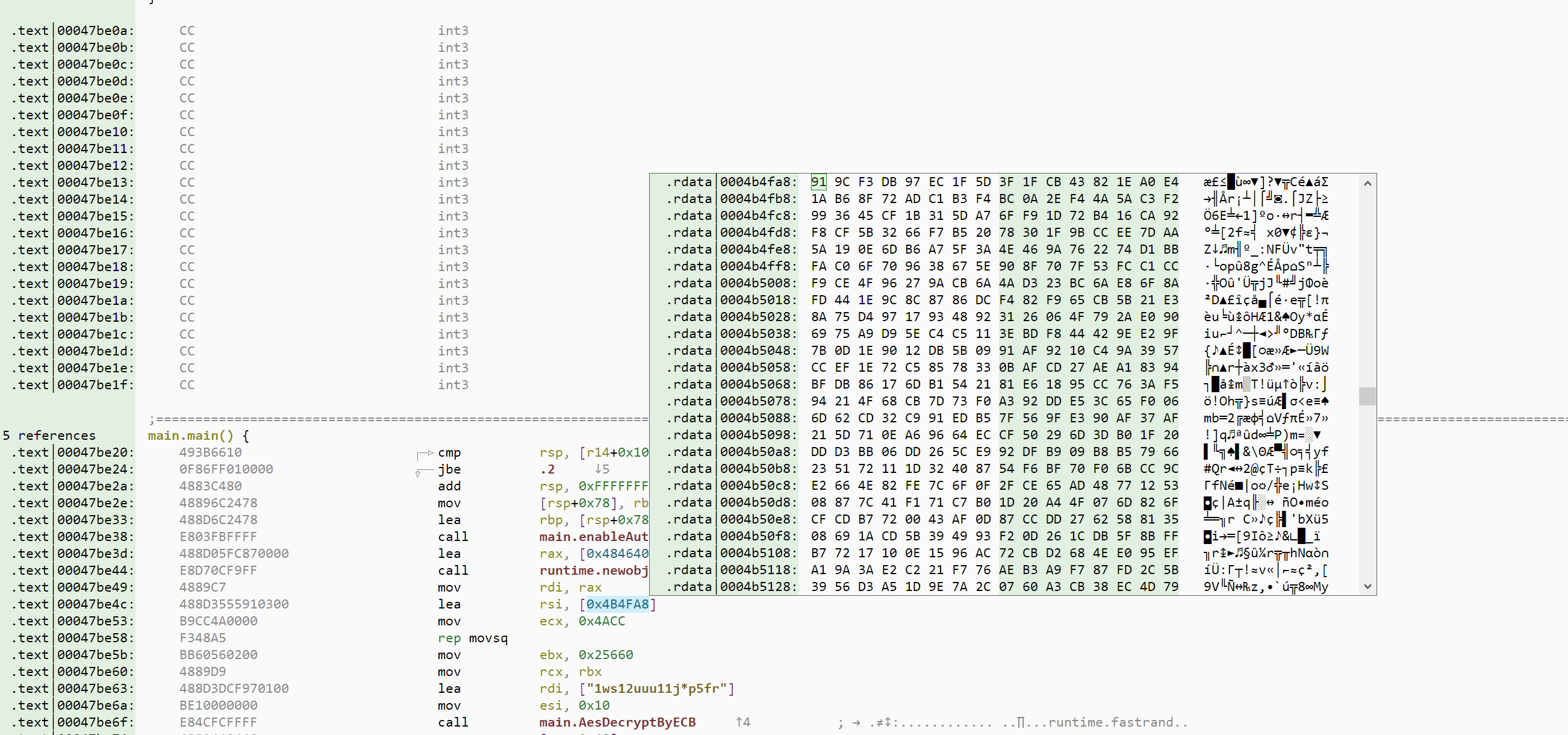
So let's see if our models perform better this time!
| model | usage (tokens/tools) | time | total cost | Unpacked chain | total |
|---|---|---|---|---|---|
| gemini-3.1-pro-preview | 258k (24 calls) | 3/4 (73s) | 3.5/4 (0.27€) | 12/12 | 18.5/20 |
| gpt-5.5 | 415k (61 calls) | 2.2/4 (132s) | 2.5/4 (0.74€) | 12/12 | 16.8/20 |
| mimo-v2.5-pro | 913k (59 calls) | 0/4 (481s) | 3.3/4 (0.33€) | 12/12 | 15.3/20 |
| claude-opus-4.7 | 447k (23 calls) | 2.7/4 (96s) | 0/4 (2.33€) | 12/12 | 14.7/20 |
| qwen3.6-plus | 862k (41 calls) | 0/4 (984s) | 3.3/4 (0.36€) | 8/12 (stopped at the donut) | 11.3/20 |
| nova-2-lite-v1 | 135k (12 calls) | 3.7/4 (21s) | 3.9/4 (0.04€) | 2/12 (says AES and packed) | 9.6/20 |
| grok-4.3 | 30k (3 calls) | 3.8/4 (14s) | 3.9/4 (0.03€) | 0/12 | 7.8/20 |
| minimax-m1 | 847k (39 calls) | 0.7/4 (248s) | 3/4 (0.48€) | 4/12 (got payload and key, failed AES decrypt) | 7.7/20 |
| deepseek-v4-pro | 1036k (16 calls) | 1.1/4 (221s) | 1.3/4 (1.35€) | 4/12 (got payload and key, failed AES decrypt) | 6.4/20 |
This malware was analysed pretty well overall.
Unpack #4
- Sample:
- 4109d17d439e425d24e9d11956adcc63ff8e24ccfffe21dd8c5431fe969d2783 (VT, Bazaar)
- Type:
- PowerShell script
- Description:
- PowerShell -> Base64 -> Gzip -> PowerShell -> Base64 -> Xor35 -> Cobalt Strike
I don't know about you, but I'm tired of binaries, so let us analyse a small script for a change. Here we have a 3-stage loader:
- The first stage is a PowerShell script that will base64-decode and gunzip a large string
- The second stage is another PowerShell script that will base64-decode and XOR a large string
- The third stage is a Cobalt Strike beacon
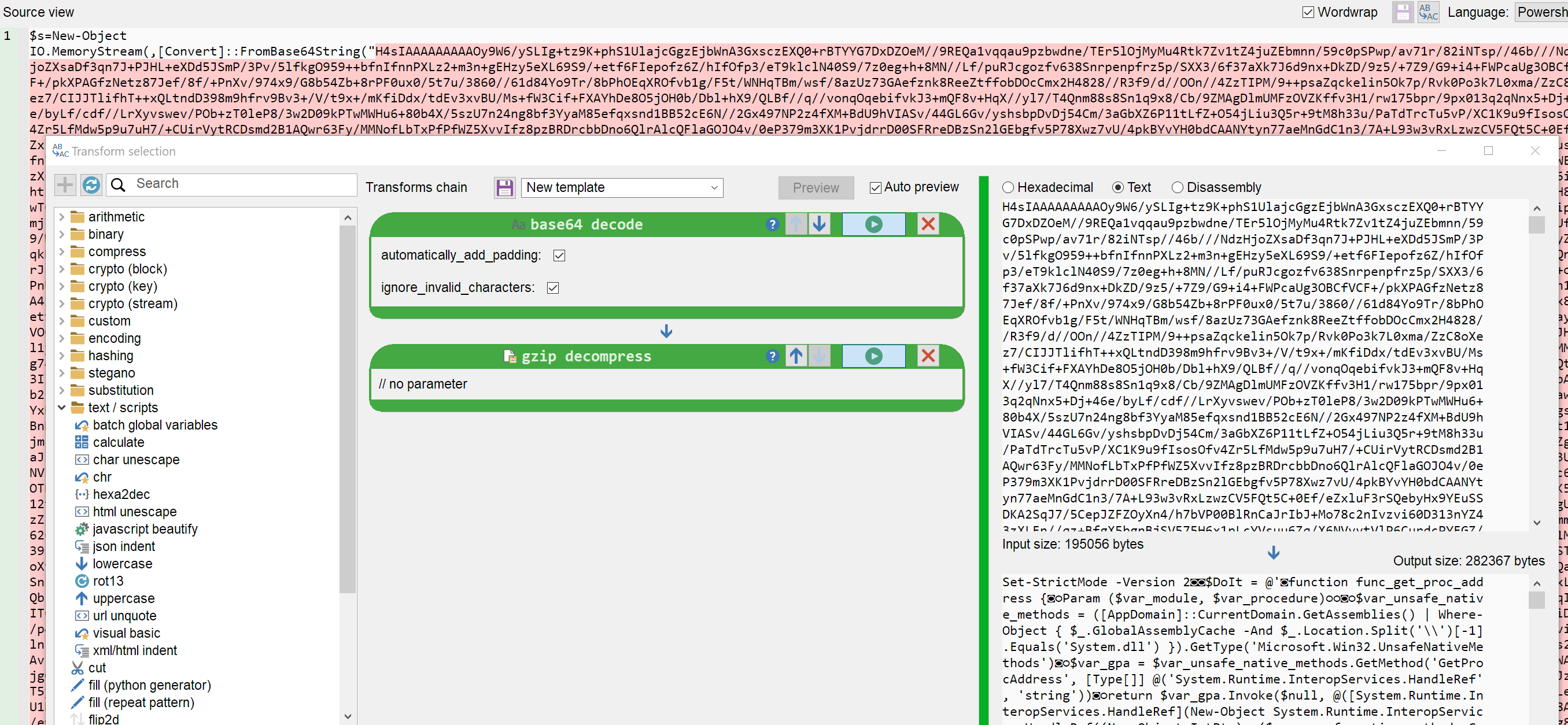
Rather easy BUT there is a catch. Malcat is not really well suited to analysing text files. The models will be able to read the content of the text file and call Malcat's transforms, but that's it: no anomalies, no analysis, no Kesakode. They are basically on their own! So let us see how they perform under these conditions:
| model | usage (tokens/tools) | time | total cost | Unpacked chain | total |
|---|---|---|---|---|---|
| gpt-5.5 | 411k (75 calls) | 1.5/4 (188s) | 2.5/4 (0.76€) | 12/12 | 16/20 |
| claude-opus-4.7 | 562k (34 calls) | 1.8/4 (166s) | 0/4 (2.98€) | 12/12 | 13.8/20 |
| mimo-v2.5-pro | 869k (69 calls) | 0/4 (673s) | 3.3/4 (0.36€) | 7/12 (second stage, said XOR) | 10.3/20 |
| nova-2-lite-v1 | 60k (8 calls) | 3.9/4 (8s) | 4/4 (0.02€) | 0/12 (ofc it says clean) | 7.8/20 |
| grok-4.3 | 19k (3 calls) | 3.8/4 (14s) | 4/4 (0.02€) | 0/12 | 7.8/20 |
| gemini-3.1-pro-preview | 822k (62 calls) | 0.9/4 (235s) | 2.8/4 (0.61€) | 4/12 (complains about context size for stage 1) | 7.7/20 |
| deepseek-v4-pro | 829k (54 calls) | 0/4 (1499s) | 1.6/4 (1.2€) | 6/12 (got to second stage) | 7.6/20 |
| qwen3.6-plus | 851k (43 calls) | 0/4 (549s) | 3.4/4 (0.32€) | 4/12 (complains about context size for stage 1) | 7.4/20 |
| minimax-m1 | 842k (48 calls) | 0.4/4 (273s) | 3/4 (0.49€) | 2/12 (truncated gzip) | 5.4/20 |
Besides GPT 5.5 and Opus 4.7, most models had issues with this sample. Two of them complained about the context size, saying that the stage 1 payload would not fit in their memory (Gemini 3.1 Pro and Qwen 3.6+). But to me, that just displays an error in their strategy. For such large obfuscated scripts, they should not load the whole script in their context window; that is just wrong. They should instead load it like any binary and read small amounts of text each time.
Unpack #5
- Sample:
- ee0f0f2f089ee0594da5750bb4e342c34d703ea045ed80c3b73c81d2f3de8bd4 (VT, Bazaar)
- Type:
- MSI installer
- Description:
- MSI -> CAB -> NSIS -> License.txt (obfuscated pyc) -> hex decode -> XOR -> reverse -> b64 -> zlib -> PowerShell -> AES -> some .NET shit I don't remember (see basic report)
For the last unpacking challenge, I've chosen a hard one ^^ A very long chain: an MSI installer that contains an NSIS installer (and a small start.exe .NET launcher). The NSIS installer packs a decoy installer, a full Python distribution (with a renamed python.exe) and a couple of obfuscated .PYC files named License.txt and License1.txt. The Python bytecode embeds a huge hex-encoded string that gets decrypted to a PowerShell script, which injects a .NET malware that, if I'm being honest, I forgot everything about.
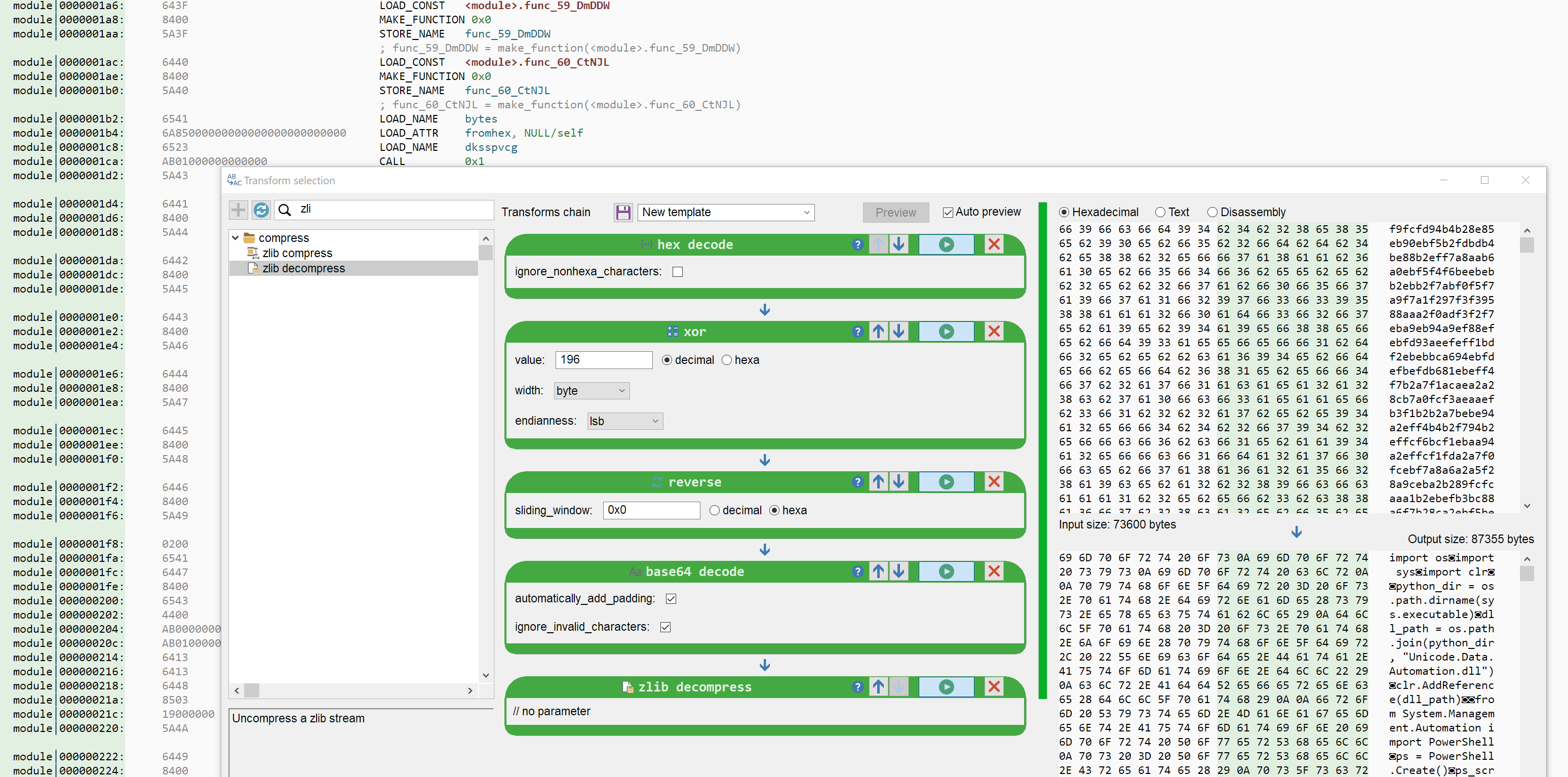
In only 800k tokens, this will be tough for our models. I'll already be impressed if they manage to identify the License*.txt files :D I'll give full points if they manage to get to the PowerShell stage.
NB: Malcat does not (yet) embed a Python decompiler, so they'll have to RE Python bytecode. Most Python decompilers fail against this sample anyway.
| model | usage (tokens/tools) | time | total cost | Unpacked chain | total |
|---|---|---|---|---|---|
| claude-opus-4.7 | 1002k (31 calls) | 1.5/4 (185s) | 0/4 (5.14€) | 9/12 (only missed the .pyc xor key value) | 10.5/20 |
| grok-4.3 | 38k (3 calls) | 3.7/4 (20s) | 3.9/4 (0.03€) | 0/12 | 7.7/20 |
| nova-2-lite-v1 | 300k (16 calls) | 3.6/4 (26s) | 3.8/4 (0.09€) | 0/12 | 7.5/20 |
| mimo-v2.5-pro | 909k (37 calls) | 1.5/4 (189s) | 2.3/4 (0.86€) | 3/12 (stopped at start.exe) |
6.8/20 |
| minimax-m1 | 836k (41 calls) | 0.4/4 (266s) | 3.1/4 (0.47€) | 3/12 (stopped at start.exe) |
6.5/20 |
| gpt-5.5 | 936k (49 calls) | 2.4/4 (123s) | 1.5/4 (1.24€) | 2/12 (thought it had to decrypt the NSIS) | 5.9/20 |
| gemini-3.1-pro-preview | 1074k (22 calls) | 2.4/4 (118s) | 1.1/4 (1.43€) | 2/12 (stopped at the NSIS) | 5.6/20 |
| qwen3.6-plus | 889k (32 calls) | 0/4 (397s) | 3.4/4 (0.31€) | 2/12 (stopped at the NSIS) | 5.4/20 |
| deepseek/deepseek-v4-pro | 904k (62 calls) | 0/4 (691s) | 2.2/4 (0.92€) | 3/12 (stopped at start.exe) |
5.2/20 |
This one definitely got the LLMs confused! To be honest, my prompt may be at fault, since some of them thought they had to decrypt the NSIS overlay instead of just opening it like any other virtual file in Malcat. Anyway, well done Claude, who almost made it to the PowerShell. It just could not figure out what the value of the XOR was, but it got the whole decryption chain correct otherwise, neat!
Summary
The static unpacking event was definitely more of a challenge for our models. And it showed in the scores. Opus 4.7 is the clear winner there, even if, to be honest, you can't really judge with just 5 examples. Two other models performed well in this use case: GPT 5.5 and Mimo 2.5 Pro:
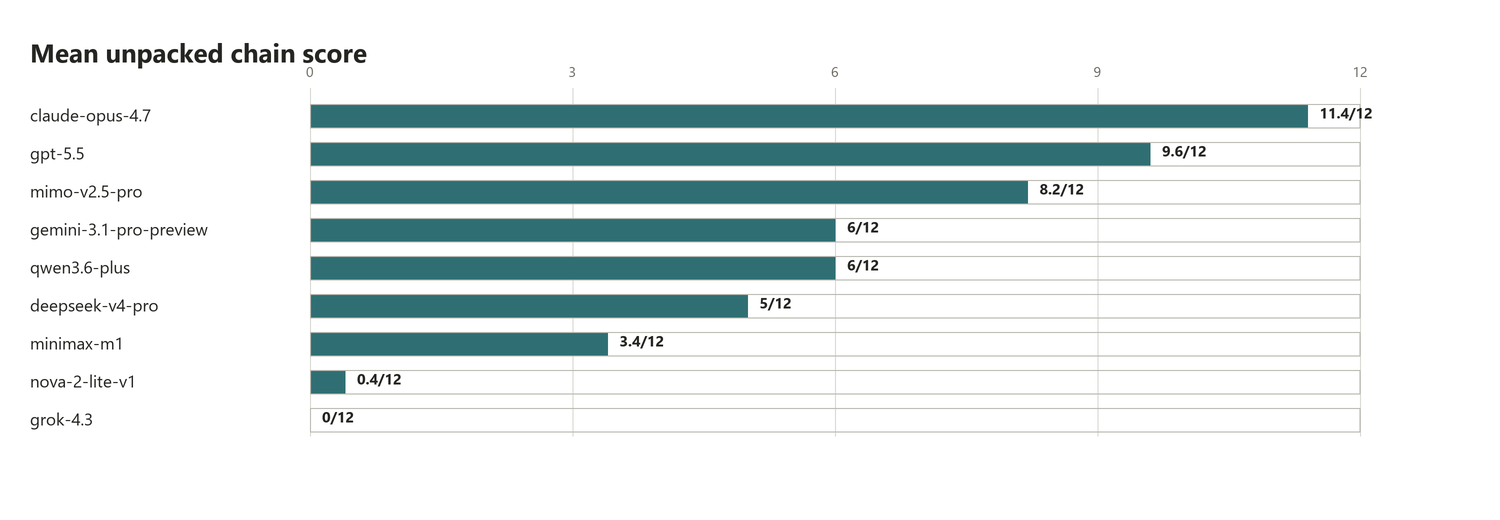
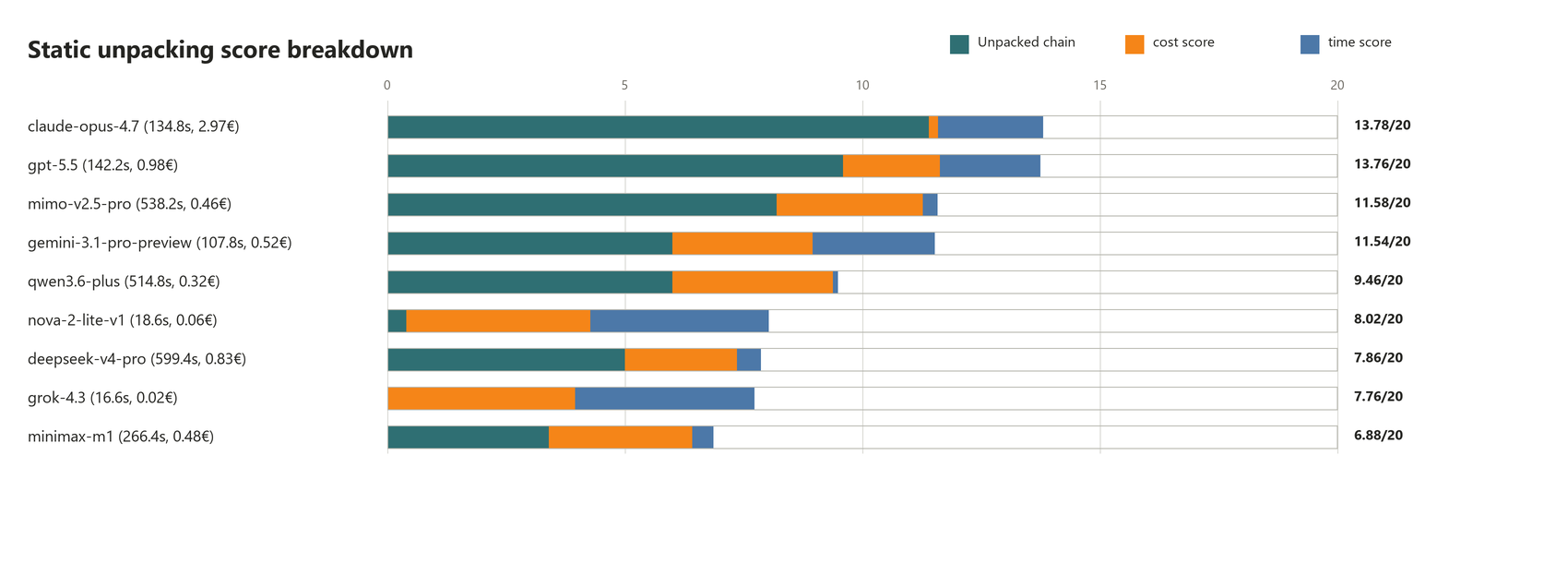
What is interesting here compared to the first benchmark is the distance between the first in the group, Opus 4.7, and the 4th, Qwen 3.6+: Claude scores almost twice as much! Models that were "good enough" for triage just fall short on these reverse-engineering-based tasks. If we take other criteria into consideration, the line becomes more blurry since Claude's very high cost is a clear drag, at three times the price of a GPT 5.5 analysis and 6 times the price of a Mimo 2.5 Pro:
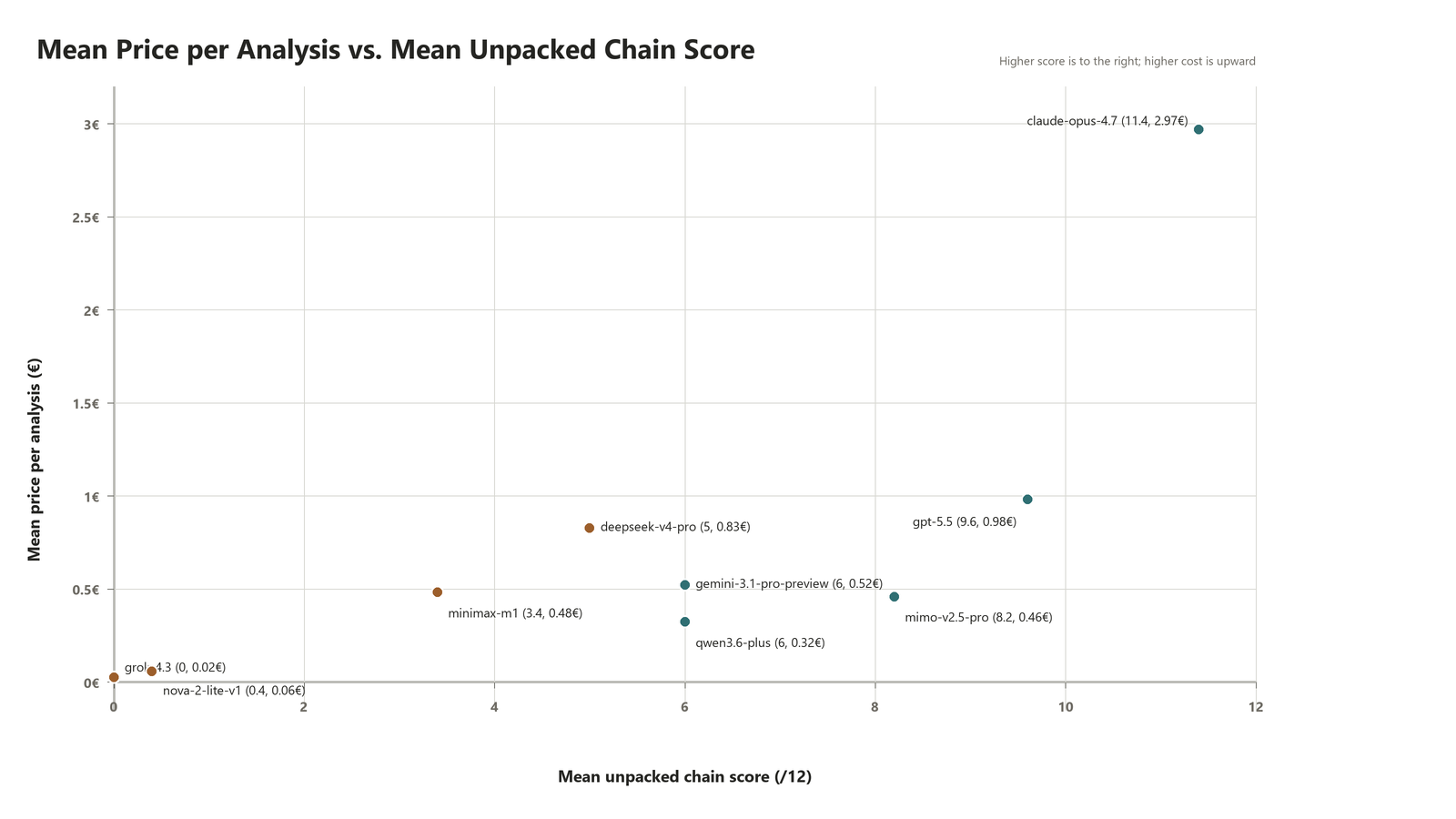
And this conclusion is further highlighted there:
What I learned
Overall, I was impressed by the results of the triage benchmark. In 2026, LLMs definitely bring a lot of value to malware triage, to the point where they could be used as second opinions in a professional context. For reverse-engineering-heavy tasks (like our static unpacking benchmark), my experience is more nuanced: LLMs are not yet autonomous analysts. But with the right tooling, they can already save a lot of time by giving good pointers.
Regarding the choice of models, while some of the results were kind of expected, like GPT and Claude being good but expensive, I was positively surprised to discover the power of Mimo 2.5 Pro, a model that I did not know anything about before running this benchmark. Not only did it perform almost as well as GPT and Opus, but it was 4 to 6 times cheaper! Respect to the engineers behind this relatively new model!
I have also learned that the advertised cost per token is only part of the story. The final cost depends heavily on how many tokens the model burns internally for reasoning and how efficiently it uses tools. For instance, Opus 4.7 and GPT 5.5 may look similarly priced on paper, yet in this benchmark Opus 4.7 cost at least twice as much.
In the end, if I had to make a decision according to this benchmark, I would:
- Use Mimo 2.5 Pro for anything scalable
- Use GPT 5.5 for triage reports when it really matters
- Use Opus 4.7 for reverse-engineering heavy tasks if money is not an issue, GPT 5.5 or Mimo 2.5 Pro otherwise
Now the benchmarking is not over! I would like to explore faster models, such as DeepSeek V4 Flash, Mimo V2 Flash or lighter ones such as NVIDIA's Nemotron 3. And as a developer, I would also like to explore other MCP servers, in order to see how much of these good scores came from Malcat, and how much from the model's reasoning. But that's for a future post!
In the meantime, I invite you to do your own benchmarks. You can test by yourself using Malcat's MCP server. And if you want to include Malcat in your pipeline, just contact us and we will be happy to assist.